-
2년동안 회사에서 한것들
2년동안 회사에서 한것들.
회사를 입사를 한지 2년 3개월째가 되어 간다. 회사를 다니면서 데이터엔지니어링을 잘하기 위해 많은 시간을 투자했다.
2년동안 한 작업들에 대해서 정리가 필요해 글을 남겨본다.
1. Csutom Data Extractor
System Spec
- 광고제작 및 모수추출시 사용되는 Data Size
- Daily - 500GB
- AdminPage
- Spring Boot (ver. 1.5.9)
- Angular Js 1.5
- WebPack
- JDBC Hive Driver
- Schduler
- Spring Boot (ver. 1.5.9)
- Quartz
- JDBC Hive Driver
- Spark Module
- Spark (ver. 1.6)
- Spark-Cassandra-Connector
DataLake를 더 활용할 수 있는 커스텀 데이터 추출기 시스템(별칭 Ad-hoc Query processor)을 만들었다. 영업에서 요청하는 조건에 맞는 유저집합을 만들어 타겟팅광고로 활용할 수 있게하는 시스템이다. 기능은 크게 두가지이다.
- 조건에 맞는 유저집합의 모수는 얼마나 되는가? (광고비소진을 위해 광고등록전에 미리정보를 본다.)
- 조건에 맞는 유저집합을 광고로 등록할 수 있게 한다.
처음 시스템을 설계했을 때는 경험부족으로 어떤 영업에서 어떤 요청을 줄지 몰라서 요청하나하나마다 SparkJob을 만들어서 사용했다.(이런 무식한 방식은 팀장님의 믿음이 있기에 가능했다.) (ex. 데이터소스에서 키워드1,키워드2등의 키워드를 사용한 유저의 집합, 광고배너를 클릭한 유저의 집합, 특정앱리스트를 설치한 사용자 등) 그리고 모수추출은 요청이 있을 때마다 spark-shell에서 추출하여 제공하였다.
이런 식으로 3개월 정도 운영하다보니, 광고등록은 400개정도 였고 모수추출요청은 500개건 정도 되었다. 하루에 적어도 5~9건을 커스텀타겟팅 관련 업무때문에 다른 일을 할 수 없었다.(정말 스트레스가 심했다.)
이런 방식으로 운영했다가는 몸이 먼저 망가질꺼 같아서.. 시스템을 개선하기로 마음 먹었다.
문제점은 세가지 정도 있었다.
- 추출 요청이 너무 많아서 혼자서 할 수 없는 환경이다.
- 반복 작업 부분이 추상화가 되어 있지 않아 코드가 지저분하다.
- 추출시간이 너무 오래걸린다.
우선 3개월동안 영업에서 들어온 요청을 분석하였다. 분석하다보니, 특정 규칙이 있었고 대략 20개정도의 패턴으로 요청을 하였다. 이를 Hive Query로 추출할 수 있는 시스템으로 개선하였고, 영업에서 직접 모수추출 및 광고등록을 할 수 있도록 AdminPage를 제작하였다.
기존에 동작하는 Schduler에 Adminpage요청을 받아 HiveQuery가 동작할 수 있는 시스템을 추가하였다. 모수추출은 광고등록 보다 빈번하게 하고 테스트성이 많아, Research클러스터에서 동작하도록 하였고, 광고등록은 HiveQuery로 추출한 유저집합을 HDFS에 저장(다른 연구용으로 사용되기 때문)한 뒤 Spark Module에서 Cassandra로 인입하는 작업을 진행하였다.
여기서 20개 패턴에서 요청 파라미터가 기본 30~40개정도 되었는데, 이작업을 효율적인 Daily 배치작업으로 하기 위해서 매턴매칭 알고리즘인
Aho Corasick패턴매칭 알고리즘을 사용하여 O(n)시간복잡도(보통 패턴매칭은 exponentiation 시간복잡도를 가짐)를 가지는 Hive UDTF를 제작하기도 하였다.(20개의 정형화된 광고패턴에서 사용되는 추출 방식은 로그에서 사용자 요청 파라미터와 매칭되는 유저 찾기 문제로 귀결되기 때문)이 UDTF 방식(later view)을 사용하지 않았다면 약 4000개되는 커스텀광고 인입 배치작업을 할 수 없었을 것이다.
커스텀타겟팅 시스템은 처음으로 오너쉽을 가지고 1부터 100까지 혼자한 작업이다. 그래서 더 애착있고, 사업적으로도 많은 성과를 보여준 시스템이였다.(시스템 등장 이후 커스텀타겟팅이 주력상품으로 되었다.)
현재는 이 시스템을 기반으로 데이터 장사를 하기 위한 시스템으로 확장시키는 작업을 하고 있다.
그래서 코드리펙토링 과정과 외부와 통신을 할 수 있는 인터페이스를 제작하는 작업을 하고 있다.
2. High Performance API Server
System Spec
- API서버
- Spring Boot (ver. 1.5.9)
- Cassandra
- 2.x -> 3.9
타겟팅 광고에서 사용되는 모든 데이터는 BID, ADID(비식별 유저 키)를 키로 Cassandra에 저장된다. 그리고 가장큰 Mission이 광고서버(DSP)에서 유저ID API서버로 요청하면 100ms안에 Cassandra에 저장되어 있는 해당유저에 관련된 모든 유정정보를 전달해야한다.
여기서 100ms라는 조건은 온라인광고를 하기위한 제약사항이다. (Response Time이 100ms가 넘으면 Timeout으로 간주한다.)
처음 팀에 왔을 때 하루 평균 API서버로 광고서버(DSP)에서 보낸 요청수는 1억건 정도였다.
이 시절에는 4대의 API서버는 ORM으로 Cassandra 데이터를 가져와도 Timeout ratio가 하루 평균 0.3%정도 였다.
하루 평균 요청수가 3억건이 되었을 때 Timeout ratio가 2~3%로 증가하였고, Timeout ratio가 1%이하로 떨어질때까지 API서버를 증설하기만 하였다. 그렇게 API서버는 10대가 되었다. 그리고 ORM으로 되어 있는 Cassandra 질의부분을 Template방식으로 변경을 하여 API부담을 덜어주었다. 하지만 결과는 미비하였다.
하루 평균 요청수가 6~7억건이 되었을 때 Tiomout ratio가 4~5%로 증가하였고, API서버 추가보다는 근본적인 개선이 필요하였다. 여기서부터 개선작업이 시작되었는데, 크게 두가지를 생각하고 작업하였는데,
- Cassandra Compaction 및 GC(CMS GC사용)가 발생하는 동안 select 지연을 Heap size를 늘려서 개선하였다.
- API로 요청하나당 Cassandra로 12개의 select 요청이 동기로 처리되는 부분을 비동기요청으로 개선하였다.
Cassandra Compaction시 발생하는 GC를 개선하고자 G1로 적용해 테스트를 했지만 fullGC횟수는 줄었지만 fullGC 처리시간은 오히려 더 길어졌다. 그래서 공식Doc에서 추천하는 방식인 기존 CMS GC에서 heapSize를 4G -> 8G로 늘려보았다. 이때는 0.8~1%로 타임아웃 비율이 줄어들었다. 여기서도 만족할 수 있었지만 더 개선하고자 하였다.
API로 요청하나당 12개의 질의를 Cassandra에 한다. 이때 각각의 쿼리가 순차적으로 실행된다. 즉 쿼리결과 얻거나 오류가 발생하기 전까지 blocking이 된다. 이부분을 개선할 필요가 있었다. Counter자료형을 사용하는 필드를 가지고 있는 Table에 질의할 때 응답시간이 가장많이 지연되는 것을 알 수 있었다. 그래서 12개의 쿼리를 비동기로 요청하고 callback은 한번에 모아서 처리하는 방식으로 수정하였고 각각의 future들을 callback을 기다리는 동안 90ms가 넘으면 먼저 도착한 쿼리결과만이라도 보내주어 API 처리량을 증가시켰다.
개선한 결과 10개의 API서버로 7억건의 요청을 0.3%정도의 Timeout ratio로 유지하였다. (Timeout ratio 개선 : 5~6% -> 0.3%)
현재는 Cassandra에 1억건이상의 데이터를 BulkInsert을 할때 API서버 성능 저하가 발생하는 것을 튜닝하고 있다. 즉 효율적인 Cassandra BulkInsert방법을 고민하고 있다.
3. RealTime AD Report
System Spec
- Spark Streaming (ver. 1.6)
- Kafka (ver. 0.8) 광고리포트를 실시간으로 제공하고자 제작되었고, 난 수치가 엉망진창인 실시간 리포트 레거시 코드를 받아 개선하는 작업을 진행하였다.
개선작업은 크게 두번의 작업으로 진행되었다.
- 실시간 정보를 광고서버에서 socket으로 제공 받고 있는 부분을 Kafka로 인입하여 Spark Streaming의 입력소스를 kafka로 개선한작업
- Spark Streaming를 사용하여 kafka에 있는 데이터를 읽을 때 offset 관리 문제를 개선한 작업
처음 개선한 부분은 입력소스가 socket으로 받고 있었다. 평소에는 문제가 되지 않지만 트래픽이 증가하는 시간대에서는 Spark Streaming에서 작업을 처리한다고 socket에서 데이터를 읽어오지 못하고 대기상태가 된다. 이때 socket의 버퍼를 초과하여 데이터 유실이 발생하는 현상이 발생하였다. 가장 좋은 방법은 광고서버에서 바로 kafka로 producing하는 것이지만 다른 팀에서 관여하는 부분이라. socket에서 데이터를 읽어 kafka로 쏘아주는 producer를 제작하였다.(팀원분이 작업 하셨음) 이렇게 되면 socket의 버퍼가 초과하기 전에 빠르게 kafka로 producing하여 기존 문제를 해결할 수 있었다.
난 이렇게 개선된 입력소스를 가지고, 실시간리포트 레거시코드를 개선하는 작업을 진행하였다. 처음 제작한 코드는 가장 편하게 사용할 수 있는
createStream으로 Receiver를 사용한 데이터처리 방식을 사용했다. 이는 데이터의 중복이 발생할 수 있는 여지가 있었다. (해당내용정리한 글) 데이터 정합성이 어긋나는 일들이 발생했다.(해당 job이 재시작되는 시점에 데이터가 어긋나는 일)그래서
Kafka Direct API를 사용하기로 결정하고 개선하였다. 개선한 결과 옛 레거시코드에서 제공받는 실시간 리포트보다 더 정확한 데이터를 제공할 수 있게 되었다.4. Hive Query Schduler
System Spec
- Java 1.8 Application
- JDBC Hive Driver
그림에서 Hive Query Base DataPipline이다.
팀에 배치되었을 때 많은 작업들이 다른 조직에서 관리하던 작업이였다. 그러다보니 데이터마켓에 데이터를 인입하는 데이터파이프라인 작업들이 다양한 스타일로 존재하였다.(오직 shell로만, HadoopMR이 최고야!, Spark가 최고야! 등)
데이터파이프라인 작업의 오너쉽이 우리팀으로 넘어오자 마자 한 작업이 파이프라인 작업을 통일하고 유지보수가 편리하게 하는 것이였다.
어떤 식으로 개선하면 좋을까 고민하던 중, 팀장님이 작업하고 있는 eCTR 학습기 코드를 보게되었다. 그리고 힌트를 얻었다. 팀장님은 모든 데이터 파이프라인 작업을 HiveQuery로 처리하였다. 이런 작업을 하던 중 만들어진게 있는데, 바로 Hive Query Schduler였다. Hive Query Schduler는 eCTR학습기에 사용되는 코드의 일부였지만 소스의 안전성과 failOver기능이 매우 좋아 Schduler부분만 가져와서 파이프라인정리작업에 사용하기로 하였다.
Hive Query Schduler는 Query파일을 읽고 해당 시간에 순차적으로 실행시켜주는 어플리케이션이다. 이런 작업을 수행하는 WorkFlow도구들이 많이 있지만, 다들 제한적인 기능때문에 내입맛에 맞지는 않았다. Query한줄이면 데이터파이프라인이 제작되는 기능의 편리함은 생산성 증대를 가져왔다.
5. 생산성 증대를 위한 각종 Tool
System Spec
- 대부분 Spring Boot로 제작
- 몇몇은 프레이워크가 없는 Java Application
업무를 처리하다보면 반복적으로 들어오는 요청들이 있다. 거의 대부분 테스트성 데이터 인입작업이였다. 처음 2~3번은 수동으로 해주다가 작업 중간중간에 들어오는 요청들이 내 작업흐름에 interrupt걸어 생산성 저하를 가져온다고 생각하게 되었다. 그래서 테스트 데이터를 인입할 수 있는 간단한 Tool제공하여, 요청자에게 제공했다.
그리고 자주보는 통계자료리포트는 처음에는 query를 날려 수동으로 보았지만, 매번하는 복붙엔터작업이 귀찮아 간단한 static html파일로 만들어 메일로 메일 아침 수신하도록 하였다.
기본 성격이 반복되는 작업을 되게 싫어하고 귀찮아해서, 한번딱 고생해서 반복되고 귀찮은 부분을 개선하는 방향으로 회사생활을 한것 같다.
- 광고제작 및 모수추출시 사용되는 Data Size
-
DistCp 정리
Hadoop distcp 정리
자주 이용하는 옵션만 사용해서.. 다른 옵션들도 사용하자! 편한기능이 많이 있었다..
주의할점
-
여러군데의 파일을 각각의 폴더 위치로 이동시키는 것은 불가
-
목적지(destination) 폴더에 파일이 존재하면 파일이 전달되지 않을 수도 있다.
파일 이동시 확인하도록 하자.
-
-
302 Redirect 처리
302 Redirect 처리
외부에서 제공하는 API를 사용하다보면 GET요청은 문제가없이 잘동작하는데, http로 된 URL에 POST요청을 할 경우 종종 302상태 코드를 리턴 받게 된다.
처음에는 당황했다. 302리다렉트할꺼면 제공하는 url를 처음부터 https로 주던지…쩝
3xx Redirect
301과 302가 존재하는데, 301 redirect는 기존 URL를 영구적(Permanent)으로 옮겼을 때 사용하고 302 redirect은 URL를 일시적(Temporary)으로 옮겼을 때 발생한다.
301 redirect은 api호출하는 입장에서 크게 수정해야할 부분이 없다. 영구적으로 url이 옮겨졌으니 자동으로 새로운 URL로 연결해준다.
하지만 302 redirect를 받을 경우 이야기는 달라진다. 말그대로 임시 URL이기 때문에 호출하는 쪽에서 새로운 URL로 redirect처리를 해줘야한다.
Apahce httpclient를 사용하자
apahce httpclient 버전을 4.3이상되는 거를 사용해야지 편리하게 사용할 수 있다.
4.3아래 버전에서는 커낵션관리, redirect처리, pool관리 등 defulat값들이 정해져있지 않아 수동으로 해줘야해서 손이 많이간다.
4.2.6버전에서 302redirect를 처리한 post요청 코드이다.
private int sendPooledRequest(String requestBody, String apiURL) throws Exception, ConnectException { if (cm == null) { SchemeRegistry schemeRegistry = new SchemeRegistry(); schemeRegistry.register(new Scheme("http", 80, PlainSocketFactory.getSocketFactory())); schemeRegistry.register(new Scheme("https", 443, SSLSocketFactory.getSocketFactory())); cm = new PoolingClientConnectionManager(schemeRegistry); cm.setMaxTotal(200); cm.setDefaultMaxPerRoute(20); } HttpPost httpPost = new HttpPost(apiURL); // header httpPost.setHeader(new BasicHeader("Pragma", "no-cache")); httpPost.setHeader(new BasicHeader("Cache-Control", "no-cache")); // body StringEntity bodyEntity = new StringEntity(requestBody, "application/json", "UTF-8"); httpPost.setEntity(bodyEntity); HttpClient httpClient = null; HttpResponse response = null; int resStatus = -1; try { httpClient = new DefaultHttpClient(cm); response = httpClient.execute(httpPost); resStatus = response.getStatusLine().getStatusCode(); } catch (ConnectException ce) { //ce.printStackTrace(); if (httpPost != null) { httpPost.abort(); } throw ce; } catch (IOException ioe) { //ioe.printStackTrace(); if (httpPost != null) { httpPost.abort(); } throw ioe; } finally { if (response != null) { EntityUtils.consume(response.getEntity()); } } return resStatus; }4.5.3버전에서 302redirect를 처리한 post요청 코드이다.
public int shootRequest(ApiRequestModel apiRequest, String inputUrl) throws IOException { Gson gson = new Gson(); String requestData = gson.toJson(apiRequest); HttpPost httpPost = new HttpPost(inputUrl); httpPost.setHeader(new BasicHeader("Pargma", "no-cache")); httpPost.setHeader(new BasicHeader("Cache-Control", "no-cache")); System.out.println("request Data => " + requestData); StringEntity bodyEntity = new StringEntity(requestData, "application/json", "UTF-8"); httpPost.setEntity(bodyEntity); CloseableHttpClient httpClient = HttpClientBuilder.create().setRedirectStrategy(new LaxRedirectStrategy()).build(); CloseableHttpResponse response = httpClient.execute(httpPost); return response.getStatusLine().getStatusCode(); }4.5 버전에서는 closeable객체를 사용하고, 거의 대부분의 값들이 default로 셋팅되어 있어 크게 손볼 것이 없다.
-
RDD가 좋은 이유
RDD가 좋은 이유
누가 Spark가 좋냐고 물어본다면 좋다고 말할 것이다. 그럼 왜 좋은가라고 물어본다면 RDD를 사용하기때문이라고 말할 것이다. 그럼 RDD가 머야?라는 질문에 답변을 하고자 이글을 정리한다.
RDD이란?
RDD의 정식 명칭은
Resilient Distributed Datasets이다. Spark를 이루는 기본연산단위이다. 기존의 Mapreduce을 이용한 방식에서 iteration과 interactive job에 한계를 느껴서 시작한 프로젝트이다.큰 특징은
- Immutable, partitioned collections of records
- 스토리지 -> RDD변환 or RDD -> RDD변환만 가능
- lazy-execution (action에 해당하는 명령어가 실행되야지 transformation이 실행됨)
- Immutalbe하니 Read-Only이다. 그래서 실행계획(lineage)를 그릴 수 있고 최적화 연산을 할 수 있다.
- 실행계획(lineage)가 그려지기때문에 Fault Tolerancer가 능해진다.
- 클러스터 전체에서 공유되는 데이터 형태로 대부분 메모리에 올라가 있음 (=빠르다)
또 알아야될 것은 다음과 같다.
기존 Mapreduce를 사용할때에는 Map, Reduce연산만을 가지고 지지고 볶고 했다. 하지만 RDD를 사용한 Spark는 다양한 요구사항을 처리할 수 있다.(MR, Pregel, DryadLINQ, Iterative MR, SQL, Batched Stream Processiog)
그래서 RDD가 먼가요?라는 질문의 한줄 답변은 다음과 같다.
fault-tolerant & efficient한 램스토리지이다.
Reference
-
Checked Exception과 Uncecked Exception 정리
Checked Exception과 Uncecked Exception 정리
1. 예외란? (Error vs Exception)
먼저 오류(Error)와 예외(Exception)의 개념을 정리하자.
오류(Error)는 시스템에 비정상적인 상황이 생겼을 때 발생한다. 이는 시스템 레벨에서 발생하기 때문에 심각한 수준의 오류이다. 따라서 개발자가 미리 에측하여 처리할 수 없기 때문에, 어플리케이션에서 오류에 대한 처리를 신경 쓰지 않아도 된다.
오류가 시스템 레벨에서 발생한다면, 예외(Exception)는 개발자가 구현한 로직에서 발생한다. 즉, 예외는 발생할 상황을 미리 예측하여 처리할 수 있다. 개발자가 처리할 수 있기 때문에 예외를 구분하고 그에 따른 처리방법을 명확히 알고 적용하는 것이 중요하다.
Exception Class 계층도
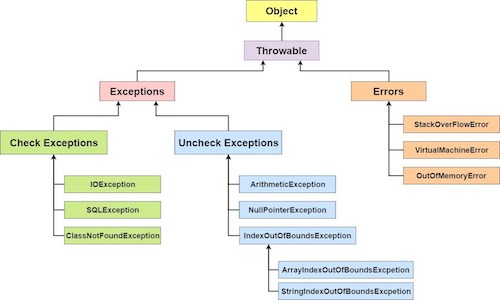
2. Checked Eception과 Unchecked Exception
Checked Exception Unchecked Exception 처리여부 반드시 예외를 처리해야함 명시적인 처리를 강제하지 않음 확인 시점 컴파일단계 실행단계 예외발생시 트랜잭션처리 roll-back하지않음 roll-back함 대표 예외 Exeption의 상속받는 하위클래스 중 Runtime Exception을 제외한 모든 예외(대표적으로 IOException) RuntimeException 하위 예외 (대표적으로 NullPointerException) 좀더 자세히 보자!
Unchecked Exception
- Code를 잘못 만들어서 생기는 예외
- 컴파일하는데는 문제없다. 실행하면 문제가 발생함
배열의 범위를 벗어난다던가(IndexOutOfBoundsException) 값이 null인 참조변수의 멤버를 호출하려 했다던가(NullPointerException) 클래스간의 형변환을 잘못했다던가(ClassCastException) 정수를 0으로 나누려 했다던가(ArithmeticException)하는 경우에 발생하는 예외들이다.
RuntimeException클래스들 중의 하나인 ArithmeticException을 try-catch문으로 처리하는 경우도 있지만, 사실 try-catch문을 사용하기보다는 0으로 나누지 않도록 프로그램을 변경하는 것이 올바른 처리방법이다. 이처럼 RuntimeException예외들이 발생할 가능성이 있는 코드들은 try-catch문을 사용하기 보다는 프로그래머들이 보다 주의 깊게 작성하여 예외가 발생하지 않도록 해야 할 것이다.
그 외의 Exception클래스들은 주로 외부의 영향으로 발생할 수 있는 것들로서, 프로그램의 사용자들의 동작에 의해서 발생하는 경우가 많다. 예를 들면, 존재하지 않는 파일을 처리하려한다던지(FileNotFoundException), 실수로 클래스의 이름을 잘못 적었다던가(ClassNotFoundException), 입력한 데이터의 형식이 잘못되었다던가(DataFormatException) 하는 경우에 발생하는 예외들이다. 이런 종류의 예외들은 반드시 처리를 해주어야 한다.
Checked Exception
- Exception 처리코드를 compiler가 check
- 프로그램 실행 흐름상 예외발생 가능성 있는 상황을 표현
- Code상의 문제가 아니라, 실행상황에 따라 발생가능성 있는 예외
- 프로그램 구현 흐름상 발생할 수 있는 예외
3. 예외 처리
try catch finally- 직접처리- 다음메소드에 던져줄 때, 명시해줘야한다.
- throws - 간접처리
- 이걸 명시해주지않으면, 예외가 있는지 없는지 모르니까 명시해 준다.
- throw - 예외생성
- Checked Exception에서 던져주는것 상위 메소드에다가 예외를 만들어서.
-
Java Default Method 정리
Java Default Method 정리
Default Method란?
공개된 API에 새로운 메서드를 추가하면 기존 구현에 새롭게 오버라이딩을 해야하는 문제가 발생하여 기존구현을 수정하지 않으면 문제가된다. 즉 다음 세개의 호환성을 만족 시키기 위해 Default Method가 존재한다.
- 바이너리 호환성 (뭔가를 바꾼 이후에도 에러없이 기존 바이너리가 실행될 수 있는 상황)
- 소스 호환성 (코드를 고쳐도 기존 프로그램을 성공적으로 재컴파일할 수 있는 상황)
- 동작 호환성 ( 코드를 바꾼 다음에도 같은 입력값이 주어지면 프로그램이 같은 동작을 하는 상황)
Default Method 사용방식은 간단하다.
public interface Example { int ex(); //메소드 앞에 default만 붙이면 된다. default boolean isEmpty() { return ex() == 0; } }Default Method를 사용하면 인터페이스에 새로운 기능을 추가해도 하위버전의 호환이 보장이 된다.
Default Method의 상속문제
다음과 같은 상황은 어떻게 해석할까?
public interface A { default void hello() { System.out.println("Hello from A"); } } public interface B extends A{ default void hello() { System.out.println("Hello from B"); } } public class C implements B, A { public static void main(String args[]) { new C().hello(); //"Hello from B"가 출력됨! } }이런 상황은 잘 없겠지만 다음 세가지 규칙을 알고 있으면 해석이 가능하다.
- 클래스가 항상 이긴다. 클래스나 슈퍼클래스에서 정의한 메서드가 디폴트 메서드보다 우선권을 갖는다.
- 1번 규칙 이외의 상황에서는 서브인터페이스가 항상 이긴다. 상속관계를 갖는 인터페이스에서 같은 시그니처를 갖는 메서드를 정의할 때는 서브인터페이스가 이긴다. 즉 B가 A를 상속받는 다면 B가 A를 이긴다.
- 여전히 디폴트 메서드의 우선순위가 결정되지 않았다면 여러 인터페이스를 상속받은 클래스가 명시적으로 디폴트 메서드를 오버라이드하고 호출해야한다.
몇 가지 예제를 살펴보자!
public interface A { default void hello() { System.out.println("Hello from A"); } } public interface B extends A{ default void hello() { System.out.println("Hello from B"); } } public class D implements A { //A hello를 재정의 void hello() { System.out.println("Hello from D"); } } public class C extends D implements B, A { public static void main(String args[]) { new C().hello(); //"Hello from D"가 출력됨!(1번규칙 때문에) } }public interface A { default void hello() { System.out.println("Hello from A"); } } public interface B { default void hello() { System.out.println("Hello from B"); } } public class C implements B,A {} /** 인터페이스 간에 상속관계가 없으므로 2번 규칙을 적용할 수 없다. 그러므로 A와B의 hello메서드를 구별할 기준이 없다. 그래서 "Error: class C inherits unrelated defaults for hello() from ypes B and A."라는 에러가 발생한다. **/그럼 충돌을 해결은 어떻게 할까?
명시적으로 어떤 인터페이스에서 사용할 지를 선택해준다.
public interface A { default void hello() { System.out.println("Hello from A"); } } public interface B { default void hello() { System.out.println("Hello from B"); } } public class C implements B,A { void hello() { B.super.hello(); //명시적으로 인터페이스 B의 메서드를 선택한다. } }마지막으로 다이아몬든 문제를 보자
public interface A { default void hello() { System.out.println("Hello from A"); } } public interface B extends A { } public interface C extends A { } public class D implements B, C { public static void main(String args[]) { new D().hello(); //어떻게 출력될까? } }D는 B와 C중 누구의 디폴트 메서드 정의를 상속받았을까? 실제로 선택할 수 있는 메서드 선언은 하나뿐이다. 따라서 “Hello from A”가 출력된다.
만약 B에도 같은 시그니처의 디폴트메서드 hello가 있다면 어떻게 될까? 2번 규칙은 디폴트메소드를 제공하는 가장 하위의 인터페이스가 선택된다고 말한다. B는 A를 상속받으므로 B가 선택된다.
그리고 B와 C모드 같은 시그니처의 디폴트메서드 hello를 가지고 있다면 충돌이 발생하므로 에러를 출력한다.