-
Spark-sumbit --files option
Spark-sumbit –files option주의사항
Spark Application을
cluster모드로 제작할 때 SparkConf 정보 등과 같이 다양한 리소스 파일을 읽는 경우가 있다.이때 사용하면 좋은 옵션이
--files옵션이다.(리소스파일 hadoop에 올리는 방법도 있지만, 매우 낭비가 큰 방식이라 선호하지는 않는다.)
deploy-mode를
client모드를 사용할때는 dirver에서 로컬 파일을 읽는 방식으로 리소스 파일을 읽어 사용하면 되지만cluster모드에서는 어떤 노드가 dirver노드가 될지 모르기 때문에 로컬 파일를 읽는 방식 처럼 사용하기는 힘들다.이때 사용하는 방식이 spark-submit옵션 중에
--files옵션을 사용하는 것이다.아래와 같이
--files다음에 리소스파일 path를 주면 사용이 가능하다.spark-submit \ --class ${class} \ --name "${appName}_${date}_${type}" \ --master yarn \ --deploy-mode cluster \ --files ${filteringFile} \ ${runjar}spark-core소스를 보면
--files로 deploy된 리소스파일은 각각의 executors에서 사용이 가능하다고 나온다. 즉 spark context로 배포되기때문에 어느 시점에서 로컬 파일처럼 읽어도 사용이 가능하다.spark application에서
Files.newBufferedReader(Paths.get(fileName))으로 읽어서 사용하면 된다.다만 주의할 점은 다음과 같다.
//files로 배포되고 각 executor에 저장된 localFilePath val executorLocalFilePath = SparkFiles.get(fileName); //아래 코드는 NotFoundFileException을 발생시킨다. Source.fromFile(executorLocalFilePath)--files옵션으로 배포된 file을 읽을때는 Path에 fileName만 주면 상대경로로 file을 찾아준다.절대경로 file 찾기란 쉽지 않으니,, 상대경로를 사용하자!!
//files로 배포되고 소스에서 사용할려면 fileName만 주면 된다. Source.fromFile(fileName)(이것 때문에 많은 시간을 보냈다.ㅠㅠ)
추가 사항 FileName
alias설정spark-submit \ --class ${class} \ --name "${appName}_${date}_${type}" \ --master yarn \ --deploy-mode cluster \ --files fileName#aliasName \ ${runjar}--files옵션 파라미터에#을 사용하면#뒤 String이 alias로 사용된다.alias는cluster모드에서만 사용이 가능하고 소스에서 사용할 때는aliasName으로 호출해서 사용한다. (fileName으로는 접근 안됨)//files로 배포되고 소스에서 사용할려면 aliasName을 넣어줘야한다. Source.fromFile(aliasName)
-
SpringBatch 정리
SpringBatch
Batch특징
- 특징
- 대용량 데이터 처리
- 사람의 조작없이 자동으로 처리
- 주기적 실행
- 배치실행의 예
- 신용카드 청구서 발행
- 마켓팅 이메일 발송
-> 배치 사용하기 전에 배치를 꼭 사용하는가를 먼저 생각하기
Spring Batch
- 많은 오픈소스가 웹기반 프레임워크에 집중
- 재사용 가능한 표준 배치 아키텍처가 없었음
- Accenture의 일괄 처리 아키텍처와 스피링 프로그래밍 모델을 통합하여 배치 프레임워크 개발
- 개발자는 비지니스 로직에 집중하고 일괄 처리 인프라는 프레임워크에서 관리
Domain Lang귀지
Job
- Setp container
- step구성
- 재시작 여부
- Job instance
- Job + Job parameter
- Job execution
- Job instance의 실행을 기술
- 실행결과, 시간등의 데이터
- 재시작등으로 1:n 관계가능
Step
- 독립적인 실행 단계
- 배치처리를 정의하고 제어하는데 필요한 모든 정보를 포함
- Job은 하나 이상의 Step으로 구성
- ItemReader
- ItemProcessor
- ItemWriter
개발자가 실제로 개발하는 부분 Tip은 복잡한 step을 만들때 간단한.step을 여러개 만들어서 만드는게 낫다 배치를 만들때 어떻게 잘 나눌까?를 고민하기
ExecutionContext
- Key-Value Store
- SpringBatch 프레임워크에서 자동으로 영속성 관리
- JobScope VS StepScope
저장소 개념으로 사용
Persistent MetaData
- JobRepository
- JobInstance, JobExecution, StepExcution 등의 CRUD
- JobExplorer
- 읽기전용
- JobOperator= JobRepository + JobExplorer
Job의 영속성관리 할때 사용 DAO라고 보면 됨
Job
JobRepository
- DB이용
- Table Prefix 설정가능
- 지원하는 DB타입이 정해져있음
- 지원하지 않는 dB타입을 사용하는 경우 (CUBRID)
- JobRepositoryFactoryBean 이용
- 호환되는 적당한 타입을 강제로 설정
- DB를 이용하지 않는 경우
- SimpleJobRepository 안의 Dao들을 구현해서 사용
- MapJobRepository (jenkins사용하는 경우)
- 인메모리 저장소 = 휘발성
- ResourcelessTransactionmanager 사용해야함
Job meta데이터를 어디에 저장할 것인가를 결정하는 인터페이스임
Job Launcher
- job을 실행하는 인터페이스
- 기본제약사항
- jobExcution이 생성되었으면 Job실행결과와 상관없이 Execution을 리턴함
- 이전에 정지된 Execution이 있었으면 새로 만들지 않고 그걸 실행
- Exception은 Job실행 시작과정에서 에러가 발생한 경우만 발생
- jobInstance가 이미 완료되었거나, 실행중인 경우
- Parameer가 Null이거나
- 파라미터 validation이 실패한 경우
- 그외는 Execution을 리턴하고 에러발생 여부는 상태를 보고 판단
- 기본구현체 SimplejobLauncher
- Async 실행 - ThreadPoolTaskExecutor주입
JobRegistry
- Job 객체에 편하게 접근할 수 있다.
- SpringBatch의 Jobinstance 개념이 아닌 Java객체
- Application context에서 bean받아 올 수도 있다. (beanName)
- job registry는 job name기반
- mapJobRegistry사용 (이거 bean등록)
- JobRegistryBeanPostProcessor로 자동 등록 (이거 bean등록)
job이름을 가져올때 사용
JobOperator
- 모니터링에 유용한 기능들을 제공
- 실행중 job목록 가져오기
- 실행, 다음실행, 재실행, 정지, 실행요약, job이름목록
- 기본구현체 SimpleJobOperator
- jobRepository, Jobexplorer, job.. bean등록 되어 있어야지 사용가능
Step
Step Restart
- 같은 job instance에서, 한번 성공한 Step은 skip
- allow-start-if-complete
- 성공여부 상관없이 항상 실행
- start-limit
- 스텝을 싱핼 수 있는 횟수 제한
Chunk-Oriented
- 하나의 데이터 -> item
- item을 모아서 chunks
- 쓰기는 chunks 단위로
- Transaction boundary
- chunk크기는 Step에설정
- commit-interval
- .chunk()
Skip Exception
- Exception발생시 실패로 만들지 않고 해당 item만 skip
- Step skip과는 다름
demo5를 보면 batch의 트렌젝션을 볼 수 있음
주의할점 wirte에서 error나면 chunk가 1로 변경되기 때문에 느려질수도 잇으니 적절하게 chunck크기를 조절하자 모니터링잘하구
TaskletStep
- read-process-wirte 형태가 아닌 작업인경우
- 디비프로시저 실행
- 스크립트 실행
- 단순 sql업뎃
- RepeatStatus
- 반환값이 FINISIHED일때 까지 반복 실행됨
- 각 반복마다 트랜잭션 생성
Partition
- partition을 나누면 read도 멀티쓰레드도 가능
- 특징
-
Spark To Cassandra Insert 작업 개편기(수정)
Spark To Cassandra Insert 작업 개편기
<이야기를 시작하기 전에 대량 Insert작업의 문제점>
Datastax에서 제공하는
spark-cassandra-connector_2.11을 사용하여 2억 Row이상이 되는 파일을 읽어 Cassandra에 Insert하는 작업이 있다. 이 작업은 Daily로 진행 된다.회사 클러스터 자원을 사용했을 때 작업 시간은 대략 30분 정도이다. 하지만 이 작업을 할 때 Cassandra Read 기능은 거의 사용할 수 없을 정도로 불능 상태가 된다.
해당 작업이 수행할 동안 Cassandra의 Read Latency는 다음과 같다. (오전7시30분~ 오전8시까지)
해당 작업이 2억Row가 되는 데이터를 한번에 Insert하는 작업이기 때문에 Spark-Cassandra-connector에서
throughput_mb_per_sec옵션으로 insert throughtput양을 조절해도 워낙 들어가는 양이 많아서 Network I/O 부하가 심해지고 memTable에 작성되는 내용이기 때문에 Memory 사용량 증가와 잦은 compaction으로 C* 전체의 성능이 저하되는 현상이 있다.

즉 C*를 사용하는 Data-API서버의 Response Time을 개선하고 싶은 것이다.
아래는 Data-API서버에 Response Time이 100ms가 넘는 비율을 나타낸 그래프이다.
7시 Bulk Insert작업이 동작하는 시간이다.
일명 불기둥(7시 bulk insert작업동안 C*의 Read성능이 떨어져 API Response Time이 100m가 넘는 것)을 제거하는 것이 이번 프로젝트에 목표다.

기존 방식에서 Read성능이 떨어지는 이유를 write path와 read path보면 알 수 있다.
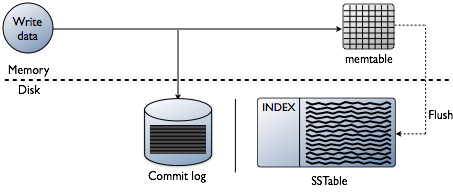
Write path
- client와 node의 process
- client에서 접속한 node가 coordinator의 역할을 하게 된다
- coordinator node는 partitioner를 이용하여 replica node를 찾고 지정된 consistency level을 만족할 만큼의 replica node를 찾지 못하면 바로 에러를 반환한다
- 대상 테이블이 materialized view 테이블의 base 테이블이면 batch log를 생성하고 설정된 consistency level과 관계 없이 내부적으로 replica nodes의 quorum만큼 변경이 반영되게 한다
- coordinator node는 replica node로 write 요청을 보내고, 요청을 받은 node는 write 처리를 수행한다
- cluster가 여러 data center로 구성되어 있으면 다른 data center에 remote coordinator를 선택하여 local coordinator와 같은 처리를 하고, remote replica는 완료 응답을 original coordinator node로 보낸다
- original coordinator node는 timeout까지 replica의 응답을 기다려 client에 응답을 보낸다
- node 안에서 process
- 대상 테이블이 materialized view 테이블이면 partition에 대한 lock을 획득하여 base 테이블의 변경이 다른 write 요청에 의해 변경되지 않고 materialized view 테이블에 반영될 수 있도록 하고 partition을 읽어 materialized view 테이블에 반영할 변화량을 구성한다
- commit log를 쓴다
- 대상 테이블이 materialized view 테이블이면 batch log를 생성하고 materialized view 테이블에 변경을 반영한다
- memtable에 data를 쓴다
- row cache가 있으면 해당 row를 invalidate 처리한다
- commit log나 memtable이 threshold를 넘으면 flush를 schedule에 등록한다
- coordinator가 client로 응답을 보낸다
- schedule에 flush가 등록되어 있으면 memtable을 sstable에 쓰고 commit log를 지우고 compaction이 필요한지 체크 후 필요하면 compaction을 수행한다
Read path
- client와 node의 process
- client에서 접속한 node가 coordinator의 역할을 하게 된다
- coordinator node는 partitioner를 이용하여 replica node를 찾고 지정된 consistency level을 만족할 만큼의 replica node를 찾지 못하면 바로 에러를 반환한다
- coordinator는 dynamic snitch를 이용해 가장 빠른 replica node에 read 요청(full data)를 보내고 다른 replica node에 digest 요청을 보내 read 요청을 보낸 node의 값의 digest와 비교하여 consistency level을 만족하면 client에 응답을 보낸다
- 가장 빠른 replica node에서 받은 값의 digest와 다른 replica node의 digest 값이 다르면 가장 빠른 replica node를 제외한 다른 replica node에 read 요청(full data)를 보내고 결과를 받아 timestamp를 비교하여 각 cell마다 가장 최근값을 client에 응답으로 보내고 값이 맞지 않는 replica node(가장 빠른 replica node 포함)들에 read repair 요청을 보내 최신값으로 동기화한다
- node 안에서 process
-
row cache를 쓰고 있으면 를 확인하여 있으면 응답을 보낸다
row cache
-
row cache에 값이 없으면 를 체크하여 sstable에 값이 있는지 확인한다
bloom filter
-
bloom filter 확인 결과가 true라고 하더라도 는 false positive(실제로는 없는데 있다고 판단) 가능성이 있으므로 를 한 번 더 확인한다
bloom filter
key cache
- key cache에 값이 있으면 그 결과(sstable에서 partition key의 offset)를 이용하여 sstable에서 값을 찾는다
-
key cache에 값이 없으면 에서 partition key에 해당하는 partition index의 offset값을 찾는다(partition key에 딱 맞는 값을 주는 것이 아니라 starting point를 알려줌)
partition summary
- 위에서 찾은 offset 값을 이용하여 sstable에서 요청된 partition key에 맞는 값을 찾는다
- memtable에서 값을 찾고 sstable에서 찾은 값이 있으면 cell별로 최신값으로 merge한다
- row cache를 쓰고 있으면 update한다
- merge된 결과를 client로 반환한다
-
- memtable을 cache처럼 쓰지 않는 이유
- memtable의 값이 항상 최신이라고 볼 수 없다
- 새로운 row가 들어와 memtable에만 값이 있는 경우 bloom filter에서 false가 되어 바로 memtable에서 값을 찾는다
- memtable이 flush가 되어 sstable에 값이 써지면 memtable은 비워지게 된다
- 비워진 memtable에 기존에 들어왔던 row에서 일부 cell들만 update가 된다고 하면 memtable만 보고서 row에 해당하는 모든 cell의 값을 알 수 없다
- memtable은 일반적인 cache라기 보다는 sstable에 값을 쓰기 전에 임시로 값을 저장하고 있는 write-back cache의 일종으로 볼 수 있다
- memtable의 값이 항상 최신이라고 볼 수 없다
spark-cassandra-connector에서 C*에 데이터를 Insert하는 방식은 RDD를 mapPartition 돌면서 Insert문을 만들어 C*에 질의하는 방식이다. 그렇기 때문에 MamTable에서 SSTable로 가는 Flush가 많아지고 SSTable이 많아지면 Compaction수가 많아져 Read작업에 사용될 Memory가 부족해 wirte작업이 끝날때 까지 Read Latency의 값이 매우 크게 나타난다. 또 GC발생횟수가 증가하고, Memory에서 Disk로 Flush가 되기 때문에 System Load도 증가된다.문제는 실시간으로 C*에서 값을 가져가 사용하는 서비스에 큰 영향을 미친다.
spark-cassandra-connector에서 제공하는 방식이 아닌 새로운 방식을 모색하게 되었다. 여러가지 실험을 진행했지만 그 중 SSTableFile을 만들어 직업 C*에 Insert하는 방식을 사용하니 ReadLatency와 C*의 성능 개선을 할 수 있었다.Cassandra Bulk Insert Lib 구조
라이브러리를 제작할 때 크게 두가지 기능을 구현하면 되었다.
- Make SSTable File
- SSTable File Up Load to Cassandra
이때 Spark를 사용하여, 위 두가지 기능을 분산 처리 하도록 하였다.
작업이 순서는 다음과 같다.
- Read File
- File transform to RDD
- foreachRDD
- Bulk Insert Process
- make SSTable File
- SSTable File Up Load to Cassandra
- Delete SSTable File
작업 시간은 10분정도 이다. (기존 30분에서 20분 가량 줄어 든 시간이다.)
아래 코드는 RDD를 Iterator돌며 SSTableFile제작 → C* upload작업을 나타낸다.
public class SSTableExportProcessor implements Serializable { public static void process(Iterator<CustomTargetingFitModel> it, SparkCassSSTableLoaderClientStatement clientStatement, int TTL) throws IOException { String keyspaceName = clientStatement.getKeyspaceName(); String tableName = clientStatement.getTableName(); //ssTable Directory Path에 마지막은 keyspace/tableName으로 해야함. String tempSSTableDirectoryPath = "/tmp/" + "spark-cass-" + UUID.randomUUID().toString() + "/" + keyspaceName + "/" + tableName; File tempSSTableDirectory = new File(tempSSTableDirectoryPath); boolean makeDirCheck = tempSSTableDirectory.mkdirs(); if (makeDirCheck) { //SSTable File 생성작업 CQLSSTableWriter writer = CQLSSTableWriter.builder() .inDirectory(tempSSTableDirectory) .forTable(clientStatement.getTableSchemaStatement()) .using(clientStatement.getInsertStatement(TTL)) .build(); while (it.hasNext()) { CustomTargetingFitModel row = it.next(); List<Object> rowValues = new ArrayList<>(2); rowValues.add(row.getUid()); rowValues.add(row.getCode()); writer.addRow(rowValues); } writer.close(); //SSTable File cassandar로 load CqlBulkRecordWriter.ExternalClient externalClient = new CqlBulkRecordWriter.ExternalClient(clientStatement.getExternalClientConf()); try { new SSTableLoader(tempSSTableDirectory, externalClient, new OutputHandler.LogOutput()).stream().get(); } catch (InterruptedException | ExecutionException e) { e.printStackTrace(); } if (tempSSTableDirectory.exists()) { FileUtils.deleteDirectory(tempSSTableDirectory); } } } }

매일 오전 7시30분에 Bulk Insert작업이 시작된다. 수정한 코드는 2월 16일에 배포를 했다. SystemLoad와 GC Time이 줄어든 것을 확인할 수 있다. MemTable을 거치지 않으니 당연한 결과이다.

하지만 Read Latency는 크게 변화가 없었다. (혼자 크게 뛰는 장비는 장비 이상으로 추후 제거되었다.)
그래서 원인을 찾아보았다.

위 그래프는 C*를 Datasource로 사용하는 API서버에서 ResponseTime이 100ms가 넘는 비율을 나타낸다.
SSTable File을 이용한 Bulk insert 방식은 7시33분 1분 동안 70%가 넘는 비율이 ResponseTime이 100ms를 넘겼다.
이에 반해 Spark-Cassandra-Connector를 사용한 isnert작업은 10%대를 길게 유지하였다.
Bulk Inert한 테이블의 Compaction Strategy는
LeveledCompactionStrategy이다. 즉 많은 SSTable File이 생성되면 될 수록 Read성능이 떨어진다.(reper. datastax-doc)기존 작업은 executor하나당 1000개가 넘는 SStable파일이 생성되어 compaction 타임에 C*의 Read성능에 악영향을 미쳤을 것으로 보인다.
그래서 수정된 작업은 다음과 같다.
- Read File
- File transform to RDD
- foreachRDD
- RepartitionByCassandraReplica (option: partitionPerHost = 1)
- Bulk Insert Process
- make SSTable File
- SSTable File Up Load to Cassandra
- Delete SSTable File
즉 1만개가 넘는 SSTableFile 갯수를 Repartitions을 하여 10개로 만들어서 테스트를 하니 API에 100ms넘는 비율이 확연하게 줄어든 것을 알 수 있다.

그리고 7시 불기둥도 사라졌다.

정리
2억 Row이상의 데이터를 C*로 Insert하는 작업을 할때 line-by-line으로 memTable로 insert하는 것 보다 SSTable에 바로 write하는 것이 유리하다.
SSTable에 바로 wirte하는 것이 유리한 점
- System Load 감소
- GC time 감소
- BulkInsert 작업 시간감소로 인해 리소스 제고
- line-by-line insert 작업 보다 나은 Read Latency
새롭게 학습한 내용
C* doc에서 권장하는 Heap Size는 8GB였다. 그래서 장비의 memory에 큰 관심이 없었다. 하지만 compaction, read할때 장비의 memory가 크면 클 수록 유리하다는 것을 doc(datastax-doc)을 읽으면서 알 수 있었다.
특히 compaction이 발생할때…
그리고 SSTable File용량보다는 File갯수가 성능에 더 큰 영향을 준다. 즉 SSTableFile갯수가 적을 수록 성능에 더 유리하다.
아래는 C*에서 사용하는 Memory구조이다.
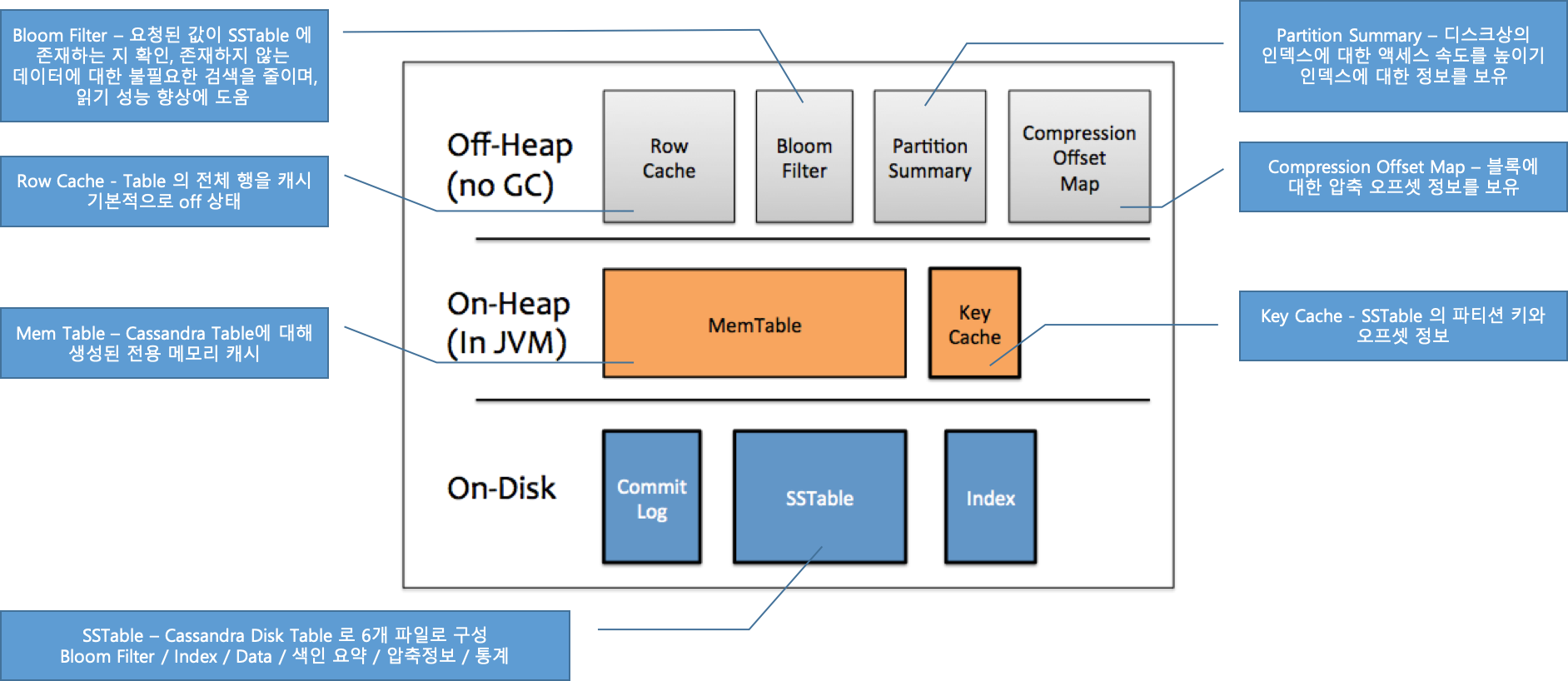
<추가> Spark Lib제작 (2019.08.26)
위 내용을 Spark Lib으로 제작하여 배포하였다.
- Spark2CassandraBulkLoad (해당 레포에 많은 관심과 기여 부탁드립니다.)
- spark-packages에도 upload하였습니다. 많은 관심 부탁드립니다.
SBT
libraryDependencies += "com.joswlv.spark.cassandra.bulk" %% "Spark2CassandraBulkLoad" % "1.0.1"Maven
<dependency> <groupId>com.joswlv.spark.cassandra.bulk</groupId> <artifactId>Spark2CassandraBulkLoad</artifactId> <version>1.0.1</version> </dependency>gradle
compile 'com.joswlv.spark.cassandra.bulk:Spark2CassandraBulkLoad:1.0.1'Usage
Bulk Loading into Cassandra
// Import the following to have access to the `bulkLoadToCass()` function for RDDs or DataFrames. import com.joswlv.spark.cassandra.bulk.rdd._ import com.joswlv.spark.cassandra.bulk.sql._ // Specify the `keyspaceName` and the `tableName` to write. rdd.bulkLoadToCass( keyspaceName = "keyspaceName", tableName = "tableName" ) // Specify the `keyspaceName` and the `tableName` to write. df.bulkLoadToCass( keyspaceName = "keyspaceName", tableName = "tableName" )
- client와 node의 process
-
Cassandra CqlBulkOutputFormat사용법
Cassandra CqlBulkOutputFormat사용법
도입배경
- Cassandra에서는 Spark connector, cqlsh 등 다양한 방법의 데이터 업로드 방법을 제공하나 대부분 insert query를 만들어 Cassandra에 실행하는 형태임.
- 많은 수의 query가 발생할 경우 Network I/O 부하가 심해지고, Cassandra의 Memory 사용량 증가와 잦은 compaction으로 인해 성능 저하가 발생함.
- 이를 방지하기 위해 Cassandra는 외부 서버에서 SSTable을 만든 후 올리는 SSTableLoader라는 Tool을 제공함.
- 그러나, 외부 서버에서 SSTable 생성시 많은 Memory 사용과 CPU 점유률로 인해 부하 분산을 고민하게 되었음.
분산 환경에서 Cassandra bulk 업로드 방법들
- CqlBulkOutputFormat, CQL3 based, easier to program, requires C* V2+ and JDK 7 in Hadoop environment
- BulkOutputFormat, thrift based, less abstraction and needs more low-level work, provided in C* V1 and OK with JDK 6
- CqlSSTableWriter + SSTableLoader, CQL3 based, easier to program, but no managed parallelism, requires C* V2 but no need for Hadoop environment, multi-thread/parallel computing mechanism would required for scalability
[출처: https://shenghuawan.wordpress.com/2015/01/20/cassandra-bulk-loading-summary/]
–> 3번은 분산 환경에서 적합하지 않음
–> 2번은 레퍼런스는 많으나 Cassandra 버전업 이후 deprecated 됨
–> 1번 방법인 CqlBulkOutputFormat을 이용해 개발하기로 결정함
CqlBulkOutputFormat 소스
CqlBulkOutputFormat 기본 동작
- Mapper 혹은 Reducer에서 넘어온
List<ByteBuffer>데이터를 입력으로 받음 - 전달된 데이터들은 buffer size대로 쪼개져 여러개의 SSTable 파일로 생성됨
- 생성된 SSTable들은 지정된 대역폭대로 압축되어 Cassandra에 전송됨
Mapper 구현
- CqlBulkOutputFormat은
List<ByteBuffer>로만 입력을 받으므로 Mapper(혹은 Reducer)를 Java로 구현하는 게 필요함 - Cassandra 테이블 컬럼의 데이터형에 따라 ByteBuffer로 casting 해줘야 하는데 Cassandra API 중 org.apache.cassandra.utils.ByteBufferUtil 을 사용하면 편리함
public void map(LongWritable key, Text data, OutputCollector<Text, List<ByteBuffer>> output, Reporter reporter) throws IOException { String[] dataArr = data.toString().split(delimiter); int categoryId = Integer.parseInt(dataArr[0]); String uid = dataArr[1].toLowerCase(); SimpleDateFormat sdf = new SimpleDateFormat(dateformat); long dtSeconds = 0; try { Date dt = sdf.parse(uploadData); dtSeconds = dt.getTime(); } catch (java.text.ParseException e) { } // make column data List<ByteBuffer> columns = new ArrayList<ByteBuffer>(); columns.add(ByteBufferUtil.bytes(uid)); columns.add(ByteBufferUtil.bytes(dtSeconds)); columns.add(ByteBufferUtil.bytes(score)); columns.add(ByteBufferUtil.bytes(categoryId)); output.collect(new Text(uid), columns); }CqlBulkOutputFormat 옵션
Hadoop Streaming -D 옵션으로 직접 설정하거나, -conf 옵션에 properties xml 파일로 지정함
- cassandra.output.keyspace : keyspace 이름 설정
- mapreduce.output.basename : table 이름 설정
- cassandra.columnfamily.schema.user_interest_category : table schema
ex) CREATE TABLE dmp.user_interest_category_test ( uid text, date timestamp, score float, category_id int, PRIMARY KEY (uid, date, score, category_id) )
- cassandra.columnfamily.insert.user_interest_category : insert query
ex) INSERT INTO dmp.user_interest_category_test (uid, date, score, category_id) VALUES (?, ?, ?, ?);
- cassandra.output.keyspace.username : cassandra user name
- cassandra.output.keyspace.passwd : password
- cassandra.output.thrift.address : cassandra 서버 ip 목록 (comma seperate)
- cassandra.output.partitioner.class : org.apache.cassandra.dht.Murmur3Partitioner
- mapreduce.job.user.classpath.first
- hadoop core 라이브러리와 cassandra 라이브러리 간에 충돌이 발생할 경우가 있음. guava api의 경우 사용하는 버전이 달라서 에러가 발생하므로 cassandra의 라이브러리를 우선 사용하도록 이 옵션을 true로 설정
- mapreduce.output.bulkoutputformat.buffersize
- sstable 생성시 사용하는 buffer size (기본 64MB).
- 설정값을 크게 할수록 한번에 생성되는 sstable size가 커지는 대신에 메모리 사용량이 많아서 MR 작업시 java.lang.OutOfMemoryError: GC overhead limit exceeded 에러가 발생하기도 함
- 너무 적게 설정할 경우 sstable 개수가 많아져 cassandra의 compaction이 자주 일어날 가능성이 있음
- mapreduce.output.bulkoutputformat.streamthrottlembits
- cassandra에 sstable 전송시 설정되는 bandwidth 값. (기본 0: 무한대)
- 설정하지 않을 경우 굉장히 빠른 속도로 cassandra 서버에 전송되나 cassandra 서버의 network inbound 대역폭을 전부 점유해버려 일시적으로 cassandra 서버에 큰 부하를 줄 수 있음.
- 상황에 따라 적절한 값으로 설정하는 게 중요함.
Maven build
<repositories> <repository> <id>ngnentRepository</id> <name>NMP Repository</name> <url><http://nexus.nhnent.com/content/groups/public></url> </repository> <repository> <id>mvnRepository</id> <name>mvn Repository</name> <url><https://mvnrepository.com/artifact/org.apache.cassandra/cassandra-all></url> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <scope>system</scope> <systemPath>${HADOOP_COMMON}</systemPath> <version>2.0.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-core</artifactId> <scope>system</scope> <systemPath>${HADOOP_MAPREDUCE_CORE}</systemPath> <version>0.20</version> </dependency> <dependency> <groupId>org.apache.cassandra</groupId> <artifactId>cassandra-all</artifactId> <version>2.1.15</version> </dependency> </dependencies>Hadoop Streaming MapReduce 작업 실행
Maven 빌드한 jar 파일을 포함 시키고, 작업한 Mapper class와 outputformat을 명시한다.
hadoop jar ${HADOOP_STREAMING_JAR} \\ -D mapred.job.name="dmp-interest-bulkload-"${DATE} \\ -D mapred.map.tasks=2 \\ -D mapreduce.job.user.classpath.first=true \\ -D cassandra.output.keyspace.username=${CASSANDRA_USER} \\ -D cassandra.output.keyspace.passwd=${CASSANDRA_PAWD} \\ -D cassandra.output.thrift.address=${CASSANDRA_ADDR} \\ -D cassandra.output.partitioner.class=org.apache.cassandra.dht.Murmur3Partitioner \\ -conf ${CONF_DIR}/schema_user_interest_category_app.xml \\ -libjars ${JAR_PATH} \\ -input ${INPUT_PATH} \\ -output ${OUTPUT_PATH} \\ -mapper com.toast.exchange.dmp.interest.bulkload.AppAdidBulkload \\ -reducer NONE \\ -outputformat org.apache.cassandra.hadoop.cql3.CqlBulkOutputFormatHadoop Streaming MapReduce 작업 로그
각 Map (혹은 Reduce)의 stdout 로그를 살펴보면 sstable 파일들이 생성되고, 전송된 결과를 확인할 수 있다. MapReduce작업이 실행된 data node를 접근해 생성된 sstable 파일들을 확인해볼 수도 있다.
sstable 생성로그
09:25:46.685 [Thread-11] DEBUG o.apache.cassandra.io.util.FileUtils - Renaming /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-tmp-ka-1-Digest.sha1 to /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Digest.sha1 09:25:46.687 [Thread-11] DEBUG o.apache.cassandra.io.util.FileUtils - Renaming /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-tmp-ka-1-TOC.txt to /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-TOC.txt 09:25:46.687 [Thread-11] DEBUG o.apache.cassandra.io.util.FileUtils - Renaming /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-tmp-ka-1-Index.db to /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Index.db 09:25:46.688 [Thread-11] DEBUG o.apache.cassandra.io.util.FileUtils - Renaming /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-tmp-ka-1-Statistics.db to /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Statistics.db 09:25:46.688 [Thread-11] DEBUG o.apache.cassandra.io.util.FileUtils - Renaming /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-tmp-ka-1-Filter.db to /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Filter.db 09:25:46.688 [Thread-11] DEBUG o.apache.cassandra.io.util.FileUtils - Renaming /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-tmp-ka-1-CompressionInfo.db to /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-CompressionInfo.db 09:25:46.689 [Thread-11] DEBUG o.apache.cassandra.io.util.FileUtils - Renaming /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-tmp-ka-1-Data.db to /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.dbsstable 전송로그
09:25:48.236 [StreamConnectionEstablisher:3] INFO o.a.c.streaming.StreamCoordinator - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401, ID#0] Beginning stream session with /x.x.x.x 09:25:48.235 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.streaming.ConnectionHandler - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Sending File (Header (cfId: e5ec2a50-3fd2-11e5-9d62-af38b156d6d1, #0, version: ka, estimated keys: 24064, transfer size: 2436481, compressed?: true, repairedAt: 0), file: /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.db) 09:25:48.235 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.streaming.ConnectionHandler - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Sending File (Header (cfId: e5ec2a50-3fd2-11e5-9d62-af38b156d6d1, #0, version: ka, estimated keys: 22528, transfer size: 2483732, compressed?: true, repairedAt: 0), file: /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.db) 09:25:48.236 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.streaming.ConnectionHandler - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Sending File (Header (cfId: e5ec2a50-3fd2-11e5-9d62-af38b156d6d1, #0, version: ka, estimated keys: 22912, transfer size: 2574224, compressed?: true, repairedAt: 0), file: /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.db) 09:25:48.315 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.s.c.CompressedStreamWriter - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Start streaming file /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.db to /10.161.26.40, repairedAt = 0, totalSize = 2459515 09:25:48.324 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.s.c.CompressedStreamWriter - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Start streaming file /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.db to /10.161.26.156, repairedAt = 0, totalSize = 2379097 09:25:48.325 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.s.c.CompressedStreamWriter - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Start streaming file /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.db to /10.161.26.37, repairedAt = 0, totalSize = 2482971 09:25:48.328 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.s.c.CompressedStreamWriter - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Start streaming file /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.db to /10.161.26.39, repairedAt = 0, totalSize = 2424141 09:25:48.333 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.s.c.CompressedStreamWriter - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Start streaming file /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.db to /10.161.26.21, repairedAt = 0, totalSize = 2436481 09:25:48.336 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.s.c.CompressedStreamWriter - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Start streaming file /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.db to /10.161.26.38, repairedAt = 0, totalSize = 2574224 09:25:48.342 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.s.c.CompressedStreamWriter - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Start streaming file /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.db to /10.161.26.157, repairedAt = 0, totalSize = 2483732 09:25:48.350 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.s.c.CompressedStreamWriter - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Start streaming file /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.db to /10.161.26.22, repairedAt = 0, totalSize = 2461039 09:27:24.853 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.s.c.CompressedStreamWriter - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Finished streaming file /data8/yarn/nm/usercache/irteam/appcache/application_1456906327100_79670/container_1456906327100_79670_01_000004/tmp/dmp/user_interest_category-c485093c-ef8b-4d06-b870-9465cd076a3b/dmp-user_interest_category-ka-1-Data.db to /10.161.26.38, bytesTransferred = 2574224, totalSize = 2574224 09:27:24.863 [STREAM-IN-/x.x.x.x] DEBUG o.a.c.streaming.ConnectionHandler - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Received Received (e5ec2a50-3fd2-11e5-9d62-af38b156d6d1, #0) 09:27:24.864 [STREAM-OUT-/x.x.x.x] DEBUG o.a.c.streaming.ConnectionHandler - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Sending Complete 09:27:24.876 [STREAM-IN-/x.x.x.x] DEBUG o.a.c.streaming.ConnectionHandler - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Received Complete 09:27:24.877 [STREAM-IN-/x.x.x.x] DEBUG o.a.c.streaming.ConnectionHandler - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Closing stream connection handler on /x.x.x.x 09:27:24.880 [STREAM-IN-/x.x.x.x] INFO o.a.c.streaming.StreamResultFuture - [Stream #5082a580-6023-11e6-a70e-5fc5e5829401] Session with /x.x.x.x is completeCqlBulkOutputFormat bulk 업로드 성능 측정
- 대상 데이터 : 4.5억 row수의 13G 데이터
- buffer size와 대역폭의 변화를 주고 성능 측정함
- buffer size : 64MB(기본값), 대역폭 : 0 (기본값)
- 결과 : sstable 생성 10분, 전송 5분
- buffer size : 96MB, 대역폭 지정: 1MBps
- 결과 : sstable 생성 10분, 전송 1시간 50분
-
Apache-SpringBoot 연동
Apache - SpringBoot(내장톰캣) 연동
개요
사내정보 시스템 SSO연동을 위해 Apache사용이 불가피함Part1. mod_jk를 이용한 tomcat 연동(Apache설정)
사내에서 발급받은 서버에는 기본적으로 Apahce2.2가 설치되어 있어 Apahce설치과정은 생략한다.
mod_jk를 설치과정 및 Apache설정은 다음과 같다.
1) tomcat-connectors설치
cd /usr/local/src wget http://www.apache.org/dist/tomcat/tomcat-connectors/jk/tomcat-connectors-1.2.44-src.tar.gz tar -xzf tomcat-connectors-1.2.44-src.tar.gz2) native 디렉토리로 이동
cd tomcat-connectors-1.2.44-src/native3) 컴파일
./configure --with-apxs=/usr/sbin/apxs make make installapxs path를 입력해줘야하는데, defulat는
/usr/sbin/apxs이다. 만약 이 경로에 없다면 찾아서 알맞게 입력하자.만약 없는 경우
sudo yum install httpd-devel4) httpd.conf수정
cd /etc/httpd/conf sudo vi httpd.conf(httpd.conf) 맨아래추가
LoadModule jk_module modules/mod_jk.so include conf/mod_jk.conf include conf/http_vhost.conf5) mod_jk.conf 추가
vi mod_jk.conf(mod_jk.conf)
<IfModule mod_jk.c> JkWorkersFile conf/workers.properties JkLogFile logs/mod_jk.log JkLogLevel info </IfModule>6) workers.properties 추가
vi worker.properties(workers.properties)
worker.list=worker1,worker2 worker.worker1.port=18009 worker.worker1.host=127.0.0.1 worker.worker1.type=ajp13 worker.worker1.lbfactor=1 worker.worker2.port=28009 worker.worker2.host=127.0.0.1 worker.worker2.type=ajp13 worker.worker2.lbfactor=1work가 여러개이면 woker.list에 콤마(,)구분자로 추가
7) http_vhost.conf 추가
vi http_vhost.conf(http_vhost.conf)
<VirtualHost *:80> ServerName customtargeting.nhnent.com JkMount /* worker1 </VirtualHost> <VirtualHost *:80> ServerName addinfra-site.nhnent.com JkMount /* worker2 </VirtualHost>서비스를 추가할려면
workers.properties와http_vhost.conf에 값을 추가하고 apache를 재시작해주면 된다.Part2. mod_jk를 이용한 tomcat 연동(Spring-Boot설정)
SpringBoot 1.x와 SpringBoot 2.x의 AJP포트 설정 법에 차이가 있다. 그 이유는 SpringBoot1.x에서는 내장톰캣을 기본으로 사용하고 있었지만 SpringBoot2.x에서는 내장톰캣대신에 netty를 사용하기 때문이다.
1) application.properties 값추가
tomcat.ajp.protocol=AJP/1.3 tomcat.ajp.port=18009 tomcat.ajp.enabled=true2-1) SpringBoot1.x ContainerConfig 클래스 추가
import org.apache.catalina.connector.Connector; import org.springframework.beans.factory.annotation.Value; import org.springframework.boot.context.embedded.EmbeddedServletContainerCustomizer; import org.springframework.boot.context.embedded.tomcat.TomcatEmbeddedServletContainerFactory; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class ContainerConfig { @Value("${tomcat.ajp.protocol}") String ajpProtocol; @Value("${tomcat.ajp.port}") int ajpPort; @Value("${tomcat.ajp.enabled}") boolean tomcatAjpEnabled; @Bean public EmbeddedServletContainerCustomizer containerCustomizer() { return container -> { TomcatEmbeddedServletContainerFactory tomcat = (TomcatEmbeddedServletContainerFactory) container; if (tomcatAjpEnabled) { Connector ajpConnector = new Connector(ajpProtocol); ajpConnector.setPort(ajpPort); ajpConnector.setSecure(false); ajpConnector.setAllowTrace(false); ajpConnector.setScheme("http"); tomcat.addAdditionalTomcatConnectors(true); } }; } }2-2) SpringBoot2.x ContainerConfig 클래스 추가
import org.apache.catalina.connector.Connector; import org.springframework.beans.factory.annotation.Value; import org.springframework.boot.web.embedded.tomcat.TomcatServletWebServerFactory; import org.springframework.boot.web.servlet.server.ServletWebServerFactory; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class ContainerConfig { @Value("${tomcat.ajp.protocol}") String ajpProtocol; @Value("${tomcat.ajp.port}") int ajpPort; @Bean public ServletWebServerFactory servletContainer() { TomcatServletWebServerFactory tomcat = new TomcatServletWebServerFactory(); tomcat.addAdditionalTomcatConnectors(createAjpConnector()); return tomcat; } private Connector createAjpConnector() { Connector ajpConnector = new Connector(ajpProtocol); ajpConnector.setPort(ajpPort); ajpConnector.setSecure(false); ajpConnector.setAllowTrace(false); ajpConnector.setScheme("http"); return ajpConnector; } }3) 부팅 로그 확인
10:50:32.520 [main] [INFO ] o.a.coyote.http11.Http11NioProtocol - Initializing ProtocolHandler ["http-nio-8080"] 10:50:32.538 [main] [INFO ] o.a.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8080"] 10:50:32.544 [main] [INFO ] o.a.tomcat.util.net.NioSelectorPool - Using a shared selector for servlet write/read 10:50:32.560 [main] [INFO ] o.apache.coyote.ajp.AjpNioProtocol - Initializing ProtocolHandler ["ajp-nio-18009"] 10:50:32.563 [main] [INFO ] o.a.tomcat.util.net.NioSelectorPool - Using a shared selector for servlet write/read 10:50:32.563 [main] [INFO ] o.apache.coyote.ajp.AjpNioProtocol - Starting ProtocolHandler ["ajp-nio-18009"] 10:50:32.576 [main] [INFO ] o.s.b.c.e.t.TomcatEmbeddedServletContainer - Tomcat started on port(s): 8080 (http) 18009 (http)ajp포트가 올라왔는지 확인한다.
-
Spark 실행 구성
Spark 실행 구성
Spark 실행 구성 정리
- 결과 RDD인 counts는 어떤 Action도 수행되지 않은 상태에선 내부적으로 정의된 RDD 객체들의 방향성 비순환 그래프(DAG, Directed Acyclic Graph)를 갖으며, 이것이 나중에 Action을 수행할 때 쓰임
- 각 RDD는 자신이 어떤 타입의 관계를 갖고 있는지에 대한 메타데이터에 따라 하나 이상의 부모 RDD를 가리키는 포인터를 유지, 이런 포인터들은 RDD가 모든 조상들을 추적할 수 있게 해줌
toDebugString()메소드로 RDD의 가계도 출력 가능- Spark의 스케줄러는 Action을 수행할 때 필요한 RDD 연산의 Physical Plan을 만듬
- Spark의 스케줄러는 연산되는 마지막 RDD에서 시작하여 연산해야 할 것을 역으로 추적, 모든 조상 RDD들을 연산하기 위해 필요한 Physical Plan을 재귀적으로 생성
- 그래프의 각 RDD에 대해 하나의 연산 Stage를 출력하게 되고, 이 Stage는 해당 RDD의 각 Partition들을 위한 Task들을 갖으며, 최종 결과 RDD를 연산해 내기 위해 Stage들은 역순으로 실행
-
파이프라이닝 외에도 Spark의 내부 스케줄러는 RDD가 이미 Cluster 메모리나 디스크에 Caching되어 있는 경우 RDD 그래프의 가계도를 제거
-
특정 Action을 위해 생성되는 Stage들이 모여 Job을 이룸 즉, count() 같은 Action을 호출할 때마다 하나 이상의 Stage로 구성된 Job이 생성 됨
-
한 번 Stage 그래프가 정의되면 Task들이 만들어지고 사용하는 배포 모드에 따라 다양하게 내부 스케줄러로 전송 됨
-
Physical Plan에서 Stage들은 RDD 가계도에 따라 각자 의존성을 가지게 되므로 그에 맞는 순서로 실행
-
Stage는 실행되는 Partition은 서로 다르지만 같은 일을 수행하는 Task들을 실행 시킴
- 각 Task는 내부적으로 다음과 같은 동일한 순서에 따라 수행됨
요약하면, Spark의 실행 중에는 다음과 같은 단계들이 발생
- 사용자 코드가 RDD의 DAG를 정의한다.
RDD의 연산들은 새로운 RDD를 만들고 이것들은 부모를 참조하게 되면서 이에 따라 그래프가 만들어 진다.
- DAG가 Action의 Physical Plan으로 변환되게 한다.
RDD에서 Action을 호출하면 그때는 반드시 연산이 수행되어야 한다. 이는 또한 부모 RDD에게도 연산을 요구하게 된다. Spark의 스케줄러는 RDD들이 필요한 모든 연산을 수행하도록 Job을 제출한다. 이 Job은 하나 이상의 Stage를 갖게 되며, 이는 Task들로 구성된 병렬 집단 연산들을 말한다. 각 Stage는 DAG에서 하나 이상의 RDD들과 연계된다. 하나의 Stage는 파이프라이닝에 의해 여러개의 RDD와 연계될 수도 있다.
- Task들이 스케줄링되고 Cluster에서 실행된다.
Stage들은 순서대로 실행되며 RDD의 조각들을 연산하기 위한 Task들을 실행한다. Stage의 최종 단계가 끝나면 Action이 완료된다.