-
properties 설정 및 사용
Properties 사용하기
properties는Hashtable를 상속받아 Key value로 구성 되어 있다.key와 value를
=으로 구분한다.다음은 properties 파일의 예이다.
spark.network.timeout=800 spark.driver.memory=1G spark.executor.memory=1G spark.rdd.compress=true spark.storage.memoryFraction=1 spark.core.connection.ack.wait.timeout=600 spark.akka.frameSize=50 spark.streaming.backpressure.enabled=true spark.serializer=org.apache.spark.serializer.KryoSerializer이런식으로
=를 사용하여, 구분 짓는다.다음은 properties파일을 읽는 모듈이다.
public static Properties getProperties(String configFilePath) { Properties prop = new Properties(); InputStream in = null; try { prop.load(new FileInputStream(configFilePath)); }catch (IOException e){ System.out.println("Error >>>>> can't read the configFilePath => " + configFilePath); System.exit(-1); }finally { try { if (in != null) in.close(); }catch (IOException e) {} finally { return prop; } } }for (Map.Entry<Object, Object> ele : DefaultSetting.getProperties("resources/sites.txt").entrySet()) { System.out.println((String) ele.getKey() +" ==> "+ (String) ele.getValue()); }이런식으로 HashMap에 넣어서 사용하면 편리하다.
-
StringBuilder vs StringBuffer
StringBuilder vs StringBuffer
단일 쓰레드환경에서 속도 비교
/** * Buffers : 9 * Builder : 4 * strings:21756 * * 단일 쓰레드 환경에서는 StringBuilder가 가장빠르다. */ public class StringSpeedTest { public static void main(String[] args) { long t0 = System.currentTimeMillis(); t0 = System.currentTimeMillis(); StringBuffer buf = new StringBuffer(); for (int i = 0 ; i < 100000; i++){ buf.append("some string"); } System.out.println("Buffers : "+(System.currentTimeMillis() - t0)); t0 = System.currentTimeMillis(); StringBuilder building = new StringBuilder(); for (int i = 0 ; i < 100000; i++){ building.append("some string"); } System.out.println("Builder : "+(System.currentTimeMillis() - t0)); String withString =""; for (int i = 0 ; i < 100000; i++){ withString+="some string"; } System.out.println("strings:" + (System.currentTimeMillis() - t0)); } }StringBuilder가 가장 좋은 성능을 보여줬다.
멀티쓰레드환경에서 비교
/** * Created by Jo_seungwan on 2017. 3. 1.. * StringBuilder는 java.lang.ArrayIndexOutOfBoundsException을 출력한다. */ public class StringMultiThreadTest { public static void main(String[] args) { ThreadPoolExecutor executorService = (ThreadPoolExecutor) Executors.newFixedThreadPool(10); //With Buffer StringBuffer buffer = new StringBuffer(); for (int i = 0 ; i < 10; i++){ executorService.execute(new AppendableRunnable(buffer)); } shutdownAndAwaitTermination(executorService); System.out.println(" Thread Buffer : "+ AppendableRunnable.time); //With Builder AppendableRunnable.time = 0; executorService = (ThreadPoolExecutor) Executors.newFixedThreadPool(10); StringBuilder builder = new StringBuilder(); for (int i = 0 ; i < 10; i++){ executorService.execute(new AppendableRunnable(builder)); } shutdownAndAwaitTermination(executorService); System.out.println(" Thread Builder: "+ AppendableRunnable.time); } static void shutdownAndAwaitTermination(ExecutorService pool) { pool.shutdown(); // code reduced from Official Javadoc for Executors try { if (!pool.awaitTermination(60, TimeUnit.SECONDS)) { pool.shutdownNow(); if (!pool.awaitTermination(60, TimeUnit.SECONDS)) System.err.println("Pool did not terminate"); } } catch (Exception e) {} } } class AppendableRunnable<T extends Appendable> implements Runnable { static long time = 0; T appendable; public AppendableRunnable(T appendable){ this.appendable = appendable; } @Override public void run(){ long t0 = System.currentTimeMillis(); for (int j = 0 ; j < 10000 ; j++){ try { appendable.append("some string"); } catch (IOException e) {} } time+=(System.currentTimeMillis() - t0); } }멀티 쓰레드환경에서 10000개를 append하는 작업에서
StringBuffer속도는 느렸다.그 이유는 JIT / hotspot / compiler / 무언가가 잠금을 검사 할 필요가 없다는 것을 탐지 할 때 최적화를 수행하기 때문이다.
이에 반해
StringBuilder는 java.lang.ArrayIndexOutOfBoundsException을 출력한다.정리
구분 StringBuffer StringBuilder synchronized Yes No Thread-safe Yes No performance Slow Better than StringBuffer
-
기본 RDD연산들(트랜스포메이션, 액션)
기본 RDD 트랜스포메이션
{1,2,3,3}을 가지고 있는 RDD에 대한 RDD 트랜스포메이션
함수 이름 용도 예 결과 map() RDD의 각 요소에 함수를 적용하고 결과 RDD를 되돌려준다. rdd.map(x -> x+1) {2,3,4,4} flatMap() RDD의 각 요소에 함수를 적용하고 반환된 반복자의 내용들로 이루어진 RDD를 되될려준다. 종종 단어 분해를 위해 쓰인다. rdd.flatMap(x -> x.to(3)) {1,2,3,2,3,3} filter() filter()로 전달된 함수의 조건을 통과한 값으로만 이루어진 RDD를 되돌려 준다. rdd.filter(x -> x != 1) {2,3,3} distinct() 중복제거 rdd.distinct() {1,2,3} sample(withReplacement, fraction, [seed]) 복원 추출(withReplacement-true)이나 비복원 추출로 RDD에서 표본을 뽑아낸다. rdd.sample(false, 0.5) 생략 {1,2,3}과 {3,4,5}를 가진 두 RDD에 대한 트랜스포메이션
함수 이름 용도 예 결과 union() 두 RDD에 잇는 데이터들을 합한 RDD를 생성한다. rdd.union(other) {1,2,3,3,4,5} intersection() 양쪽 RDD에 모두 있는 데이터들만을 가진 RDD를 반환한다. rdd.intersection(other) {3} subtract() 한 RDD가 가진 데이터를 다른 쪽에서 삭제한다 rdd.subtract(other) {1,2} cartesian() 두 RDD의 카테시안 곱 rdd.cartesian(other) {{1,3},{1,4},{1,5} … ,{3,5}} 기본 RDD 액션
{1,2,3,3}을 갖고 있는 RDD에 대한 기본 액션
함수 이름 용도 예 결과 collect() RDD의 모든 데이터요소 리턴 rdd.collect() {1,2,3,3} count() RDD의 요소 개수 리턴 rdd.count() 4 countByValue() RDD에 있는 각 값의 개수 리턴 rdd.countByValue() {{1,1},{2,1},{3,2}} take(num) RDD의 값들 중 num개 리턴 rdd.take(2) {1,2} top(num) RDD의 값들 중 상위 num개 리턴 rdd.top(2) {3,3} takeOrdered(num(ordering) 제공된 ordering 기준으로 num개 값 리턴 rdd.takeOrdered(2)(myOrdering) {3,3} takeSample(withReplacement, num, [seed]) 무작위 값을 리턴 rdd.takeSample(false,1) 생략 reduce(func) RDD의 값들을 병렬로 병합 연산한다. rdd.reduce((x,y) -> x+y) 9 fold(zero)(func) reduce()와 동일하나 제로 밸류를 넣어준다. rdd.fold(0)(x,y) -> x+y 9 aggregate(zeroValue)(seqOP, combOp) reduce()와 유사하나 다른 타입을 리턴한다. rdd.aggregate((0,0))((x,y) -> (x._1 + y, x._2 +1), (x,y) -> (x._1 + y._1, x._2 + y._2)) {9,4} foreach(func) RDD의 각값에 func을 적용한다. rdd.foreach(func) 없음
-
Logstash 기초
Logstash 기초
설치
최신 버전은 Download Logstash에서 다운 받으면 된다.
하지만 낮은 버전을 이용할 경우 다음 과 같이 하면 된다. 우선 해당 버전 logstash repo정보를 찾는다.
작업을 위해 2.3버전이 필요했다.링크
링크에서 설명한 것을 보면 다운로드를 위한 pulic signing key를 다음과 같이 발급받는다.
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch그리고
/etc/yum.repos.d/디렉토리에 logstash.repo파일을 다음과 같이 만들고 저장한다.[logstash-2.3] name=Logstash repository for 2.3.x packages baseurl=https://packages.elastic.co/logstash/2.3/centos gpgcheck=1 gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch enabled=1그리고
yum install logstash를 하면 logstash 2.3버전이 설치가 된다.설치는
/opt/logstash디렉토리에 설치된다.개념
logstash는 파이프라인같은 개념이다. 다양한 곳에서 Input을 받아 사용자가 가공하여 다양한 곳으로 출력 및 저장 할 수 있다.데이터가 소스에서 저장소로 이동할 때
logstash필터에서 미리 정의한 이벤트 및 구조를 정의 할 수 있다. 사용할 수 있는 라이브러리는 다양하다.즉
- input : 데이터를 받는다.
- filter : 데이터를 가공한다.
- output : 데이터를 출력한다.
이렇게 정리가 된다.
사용하기
logstash를 사용하기 위해서 데이터 소스를 가공을 정의한conf파일이 필요하다.모양은 다음과 같다.
input { . . . } filter { . . . } output { . . . }conf파일을 만들면logstash가 설치된 폴더안에 있는bin폴더에 있는logstash를 사용하면 된다../logstash -f test.conf예제
finace.yahoo.com에서 apple 주식 정보를 csv파일로 다운 받아 elasticsearch에 저장해보자
데이터는 Date, Open, High, Low, Close 등이 있다.
conf파일을 작성하면 다음과 같다.input { file { path => "/root/applestock.csv" start_position => "beginning" sincedb_path => "/dev/null" } } filter { csv { separator => "," columns => ["Date","Open","High","Low","Close","Volume","Adj Close"] } mutate {convert => ["Open", "float"]} mutate {convert => ["High", "float"]} mutate {convert => ["Low", "float"]} mutate {convert => ["Close", "float"]} } output { elasticsearch { hosts => "localhost" index => "applestock" } stdout {} }- input에서 file을 받고, 처음부터 읽겠다고 선언했다. 그리고 sincdb_path는 position을 저장하는 db의 위치인데, 사용을 안하겠다고 선언했다.
- filter에서 csv파일을
,로 구분하고 Open, High, Low, Close를 float라고 mapping을 했다. - 결과 같음 elasticsearch
applestockindex에 저장했다. 그리고 저장되는 과정을 출력했다.
다음과 같이 stdout이 되는 것을 확인 할 수 있다.
... 2017-02-20T03:08:23.445Z ip-172-31-3-227 1981-08-24,18.999999,18.999999,18.875,18.875,5768000,0.279022 2017-02-20T03:08:23.445Z ip-172-31-3-227 1981-08-21,20.375001,20.375001,20.125,20.125,10477600,0.2975 2017-02-20T03:08:23.445Z ip-172-31-3-227 1981-08-20,21.624999,21.75,21.624999,21.624999,4278400,0.319674 2017-02-20T03:08:23.445Z ip-172-31-3-227 1981-08-19,21.624999,21.624999,21.375,21.375,5168800,0.315978 2017-02-20T03:08:23.445Z ip-172-31-3-227 1981-08-18,21.875,21.875,21.624999,21.624999,4250400,0.319674 2017-02-20T03:08:23.446Z ip-172-31-3-227 1981-08-17,22.375,22.375,22.125001,22.125001,4726400,0.327065 2017-02-20T03:08:23.446Z ip-172-31-3-227 1981-08-14,23.125,23.125,22.875,22.875,6048000,0.338152 2017-02-20T03:08:23.446Z ip-172-31-3-227 1981-08-13,23.374999,23.374999,23.25,23.25,6871200,0.343695 2017-02-20T03:08:23.446Z ip-172-31-3-227 1981-08-12,24.125,24.125,24.00,24.00,6568800,0.354782 2017-02-20T03:08:23.446Z ip-172-31-3-227 1981-08-11,24.750001,24.750001,24.50,24.50,17864000,0.362174 2017-02-20T03:08:23.446Z ip-172-31-3-227 1981-08-07,25.25,25.375,25.25,25.25,2301600,0.373261 2017-02-20T03:08:23.446Z ip-172-31-3-227 1981-08-06,25.375,25.375,25.25,25.25,2632000,0.373261 2017-02-20T03:08:23.446Z ip-172-31-3-227 1981-08-05,25.875,25.999999,25.875,25.875,4373600,0.3825 ...
ElasticSearch에 Index가 생성된 것을 확인 할 수 있다.
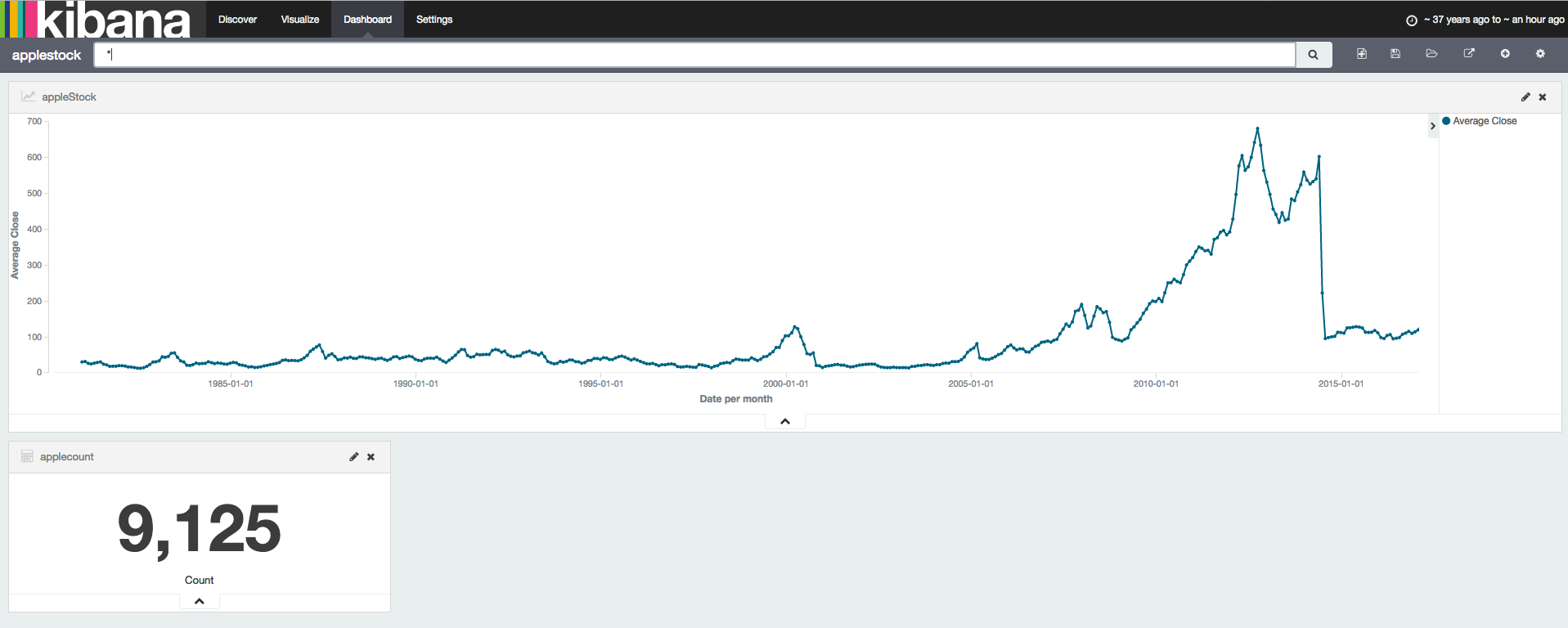
Kibana를 이용하여 apple주식데이터를 시각화를 하였다.
사용된 Document는 9125개임을 확인 할 수 있다.
Reference
-
ElasticSearch 기초
ElasticSearch 기초
설치 (ubuntu)
#fileName : ElasticSearchInstall.sh #!/bin/bash ### USAGE ### ### ./ElasticSearch.sh 1.7 will install Elasticsearch 1.7 ### ./ElasticSearch.sh will fail because no version was specified (exit code 1) ### ### CLI options Contributed by @janpieper ### Check http://www.elasticsearch.org/download/ for latest version of ElasticSearch ### ElasticSearch version if [ -z "$1" ]; then echo "" echo " Please specify the Elasticsearch version you want to install!" echo "" echo " $ $0 1.7" echo "" exit 1 fi ELASTICSEARCH_VERSION=$1 if [[ ! "${ELASTICSEARCH_VERSION}" =~ ^[0-9]+\.[0-9]+ ]]; then echo "" echo " The specified Elasticsearch version isn't valid!" echo "" echo " $ $0 1.7" echo "" exit 2 fi ### Install Java 8 cd ~ sudo apt-get install python-software-properties -y sleep 1 sudo add-apt-repository ppa:webupd8team/java -y sleep 1 sudo apt-get update sleep 1 sudo apt-get install oracle-java8-installer -y ### Download and install the Public Signing Key wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - ### Setup Repository echo "deb http://packages.elastic.co/elasticsearch/${ELASTICSEARCH_VERSION}/debian stable main" | sudo tee -a /etc/apt/sources.list.d/elk.list ### Install Elasticsearch sudo apt-get update && sudo apt-get install elasticsearch -y ### Start ElasticSearch sudo service elasticsearch start ### Lets wait a little while ElasticSearch starts sleep 5 ### Make sure service is running curl http://localhost:9200 ### Should return something like this: # { # "status" : 200, # "name" : "Storm", # "version" : { # "number" : "1.3.1", # "build_hash" : "2de6dc5268c32fb49b205233c138d93aaf772015", # "build_timestamp" : "2014-07-28T14:45:15Z", # "build_snapshot" : false, # "lucene_version" : "4.9" # }, # "tagline" : "You Know, for Search" # }위 스크립트를
./ElasticSearchInstall.sh [버전]으로 실행 실행하면 된다.기본 개념
Elastic Search Relational DB Index Databases Type Table Document Row Field Column Mapping Schema RESTfull 방식으로 사용된다.
Elastic Search Relational DB CRUD GET Select Read PUT Update Update Post Insert Create DELETE Delete Delete
1) Index 조회curl -XGET '[elasticsearch 주소]/[Index name]결과
[root@bigdataStudy]# curl -XGET localhost:9200/basketball?pretty { "basketball" : { "aliases" : { }, "mappings" : { "record" : { "properties" : { "assists" : { "type" : "long" }, "blocks" : { "type" : "long" }, "name" : { "type" : "string" }, "points" : { "type" : "long" }, "rebounds" : { "type" : "long" }, "submit_date" : { "type" : "date", "format" : "yyyy-MM-dd" }, "team" : { "type" : "string" } } } }, "settings" : { "index" : { "creation_date" : "1487474066966", "uuid" : "uFna9rNjR5S3vRKEZtEHvg", "number_of_replicas" : "1", "number_of_shards" : "5", "version" : { "created" : "2030399" } } }, "warmers" : { } } }basketballIndex정보를 볼 수 있다.record라는 Type의 정보도 함께 나오는 것을 확인 할 수 있다.2)
_update_update옵션은 Type의 Field를 추가할 때 사용한다.다음과 같은 Document가 있다
[root@bigdataStudy]# curl -XGET localhost:9200/classes/class/1/?pretty { "_index" : "classes", "_type" : "class", "_id" : "1", "_version" : 1, "found" : true, "_source" : { "title" : "Bigdata", "professor" : "Jo" } }다음과 같이
pointField를 추가하였다.[root@bigdataStudy]# curl -XPOST localhost:9200/classes/class/1/_update?pretty -d ' > {"doc":{"point":1}}' { "_index" : "classes", "_type" : "class", "_id" : "1", "_version" : 2, "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 } }결과를 확인하면 다음과 같다.
[root@ip-172-31-12-34 ch04]# curl -XGET localhost:9200/classes/class/1/?pretty { "_index" : "classes", "_type" : "class", "_id" : "1", "_version" : 2, "found" : true, "_source" : { "title" : "Bigdata", "professor" : "Jo", "point" : 1 } }추가 된 것을 확인 할 수 있다.
3)
_bulk여러개의 Document를 입력할 때 사용한다.
다음은 파일에서 값을 가져오는 방법이다.
culr -XPOST [elasticsearch 주소]/_bulk --data-binary @[파일명]
4) MappingIndex를 생성하면 mapping 정보가 빠져 있다.
[root@bigdataStudy]# curl -XGET localhost:9200/classes/?pretty { "classes" : { "aliases" : { }, "mappings" : { }, "settings" : { "index" : { "creation_date" : "1487477362931", "uuid" : "Z3HY5liZToOyUiEgRL9J4g", "number_of_replicas" : "1", "number_of_shards" : "5", "version" : { "created" : "2030399" } } }, "warmers" : { } } }class라는
Type의 mapping 값을 다음과 같이 입력하겠다.classesRating_mapping.json { "class" : { "properties" : { "title" : { "type" : "string" }, "professor" : { "type" : "string" }, "major" : { "type" : "string" }, "semester" : { "type" : "string" }, "student_count" : { "type" : "integer" }, "unit" : { "type" : "integer" }, "rating" : { "type" : "integer" }, "submit_date" : { "type" : "date", "format" : "yyyy-MM-dd" }, "school_location" : { "type" : "geo_point" } } } }입력을 다음과 같이 한다.
[root@bigdataStudy]# curl -XPUT localhost:9200/classes/class/_mapping?pretty -d @classesRating_mapping.json { "acknowledged" : true }Type의 mapping값이 입력된 것을 확인 할 수 있다.[root@bigdataStudy]# curl -XGET localhost:9200/classes/?pretty { "classes" : { "aliases" : { }, "mappings" : { "class" : { "properties" : { "major" : { "type" : "string" }, "professor" : { "type" : "string" }, "rating" : { "type" : "integer" }, "school_location" : { "type" : "geo_point" }, "semester" : { "type" : "string" }, "student_count" : { "type" : "integer" }, "submit_date" : { "type" : "date", "format" : "yyyy-MM-dd" }, "title" : { "type" : "string" }, "unit" : { "type" : "integer" } } } }, "settings" : { "index" : { "creation_date" : "1487477362931", "uuid" : "Z3HY5liZToOyUiEgRL9J4g", "number_of_replicas" : "1", "number_of_shards" : "5", "version" : { "created" : "2030399" } } }, "warmers" : { } } }5)
_searchRDBMS의
where조건 같은 느낌도 있다.curl -XGET localhost:9200/basketball/record/_search?q=points:30&pretty위는 record
type에서 points가 30인Document를 출력하게 된다.더 많은 옵션은 ElasticSearch API Doc에서 확인 할 수 있다.
6) Aggregation-
Metrics Aggregations - sum, min, max, avg을 구할 때 사용한다.
-
Bucket Aggregations - RDBMS의
Group By와 같은 기능을 제공한다.
사용법
_search옵션과 함께 사용한다.{ "size" : 0, "aggs" : { "avg_score" : { "avg" : { "field" : "points" } } } }위와 같이 Metrics Aggregation 설정 json파일을 만든다.
평균을 구하는 aggregation이다.
aggs은 aggregation을 사용하겠다는 선언이다.avg_score은 alias같은 느낌이다. 검색 결과의 field이름 이다.avg는 Metrics Aggregation에서 평균을 구하는 옵션이다.field는avg에 사용되는field값이다.
검색 결과는 다음과 같다.
[root@bigdataStudy]# curl -XGET localhost:9200/_search?pretty --data-binary @avg_points_aggs.json { "took" : 9, "timed_out" : false, "_shards" : { "total" : 15, "successful" : 15, "failed" : 0 }, "hits" : { "total" : 2, "max_score" : 0.0, "hits" : [ ] }, "aggregations" : { "avg_score" : { "value" : 25.0 } } }평균값이 나온 것을 확인 할 수 있다.
Metrics Aggregation에서
stats옵션을 사용하면 count, min, max, avg, sum을 한번에 출력한다.Bucket Aggregation예도 한번 보자
"size" : 0, "aggs" : { "team_stats" : { "terms" : { "field" : "team" }, "aggs" : { "stats_score" : { "stats" : { "field" : "points" } } } } } }이렇게 aggregation json파일을 만들었다.
aggs를 사용한다고 선언했다.terms라는 bucket aggregation의 옵션을 사용한다. 이는team이라는 필드로group by하겠다라는 뜻이다.sub aggs를 선언하고 point로 Metrics정보를 출력한다.
다음과 같이 4개의 Documents를 입력하였다.
[root@bigdataStudy]# curl -XGET localhost:9200/_search?pretty { "took" : 4, "timed_out" : false, "_shards" : { "total" : 15, "successful" : 15, "failed" : 0 }, "hits" : { "total" : 4, "max_score" : 1.0, "hits" : [ { "_index" : "basketball", "_type" : "record", "_id" : "2", "_score" : 1.0, "_source" : { "team" : "Chicago", "name" : "Michael Jordan", "points" : 20, "rebounds" : 5, "assists" : 8, "blocks" : 4, "submit_date" : "1996-10-13" } }, { "_index" : "basketball", "_type" : "record", "_id" : "4", "_score" : 1.0, "_source" : { "team" : "LA", "name" : "Kobe Bryant", "points" : 40, "rebounds" : 4, "assists" : 8, "blocks" : 6, "submit_date" : "2014-11-13" } }, { "_index" : "basketball", "_type" : "record", "_id" : "1", "_score" : 1.0, "_source" : { "team" : "Chicago", "name" : "Michael Jordan", "points" : 30, "rebounds" : 3, "assists" : 4, "blocks" : 3, "submit_date" : "1996-10-11" } }, { "_index" : "basketball", "_type" : "record", "_id" : "3", "_score" : 1.0, "_source" : { "team" : "LA", "name" : "Kobe Bryant", "points" : 30, "rebounds" : 2, "assists" : 8, "blocks" : 5, "submit_date" : "2014-10-13" } } ] } }그리고 위의 aggregation을 사용하여 검색을 해보았다.
[root@bigdataStudy]# curl -XGET localhost:9200/_search?pretty --data-binary @stats_by_team.json { "took" : 13, "timed_out" : false, "_shards" : { "total" : 15, "successful" : 15, "failed" : 0 }, "hits" : { "total" : 4, "max_score" : 0.0, "hits" : [ ] }, "aggregations" : { "team_stats" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "chicago", "doc_count" : 2, "stats_score" : { "count" : 2, "min" : 20.0, "max" : 30.0, "avg" : 25.0, "sum" : 50.0 } }, { "key" : "la", "doc_count" : 2, "stats_score" : { "count" : 2, "min" : 30.0, "max" : 40.0, "avg" : 35.0, "sum" : 70.0 } } ] } } }위와 같이
chicago팀의 stats와la팀의 stats가 출력되는 것을 확인 할 수 있다.Reference
-
-
RDBMS vs NOSQL
RDBMS? NOSQL?
- 데이터의 읽기 쓰기 등 퍼포먼스에 치중한다면 NOSQL, 트랜잭션과 같은 정합성 위주의 시스템을 사용한다면 RDBMS
- RDBMS 컬럼 변경 용이하지 않음, NOSQL 컬럼 변경 용이
- NOSQL의 경우 sorting, join, grouping, range query, index 매우 취약
- RDBMS 학습 비용 x
- NOSQL 학습 비용 소요 (운영시 어떤 장애상황이 생길지 예측이 어려움)
- NOSQL 가장 큰 장점 (Scale-Out, RDBMS보다 상대적으로 빠른 쓰기/읽기)
NOSQL 분류
[ 키 밸류형 ] redis, memcached, Oracle Coherence
[ 컬럼형 ] Cassandra, HBASE, Cloud Datastore
[ 문서형 ] MongoDB, Couchbase, MarkLogic, PostgreSQL, MySQL, DynamoDB MS-DocumentDB
[ 그래프형 ] Neo4j
DataStore 설 명 장 점 단 점 Cassandra - Facebook에 의해 2008년 아파치 오픈소스로 공개된 분산 데이터 베이스 (자바 언어 기반)
- 컬럼 단위로 관리되어 컬럼형으로 분류
- 대용량의 데이터 트랜잭션에 대해 고성능 처리가 가능(실제 트위터 MYSQL -> Cassandra로 전환)- 대량으로 쓰기가 발생하는 서비스에 좋음
- 확장성이 뛰어남
- Apache Foundation에서 개발중이며커뮤니티 활발
- Scale-Out- 최소 3대 이상 구성(클러스터 환경)
- 복잡한 조건 검색 불가
- 데이터 갱신 및 입력시 Atomic한 처리가 힘듬HBase - 대량 데이터를 우수한 성능으로 데이터 일관성을 보장하면서 다뤄야 할 때 주로 사용
- 대량 데이터 분석 및 처리를 위해 사용되는 Hadoop의 산하 프로젝트로 시작된 데이터베이스 (HDFS 및 MapReduce등과 함께 사용하기에 최적화)
- 수십 테러바이트가 넘는 빅데이터에 적합- 하둡 기반에서 동작하고 다양한 하둡 의 도구들과 상호 운영성이 좋음
- 데이터 일관성 보장 우수(상대적)- 5대 미만에서는 사용할 수 없다(대규모 전용)
- 성능이 좋진 않다 (상대적)MongoDB - MongoDB는 10gen 사에서 개발된 높은 성능과 확장성을 가지고 있는 데이터베이스
- NoSQL 데이터베이스에서는 문서형 데이터베이스로 분류(C언어 기반)
- 데이터를 입력할때 데이터 구조 정보를 포함하여 BSON(JSON을 바이너리화한것)형식으로 저장하고, key value로 사용
- NON-SCHEMA
-비정형 데이터, 파일 데이터등의 스키마프리(Scheme free)모델에서 적합
- SQL 과 비슷한 방식의 쿼리 사용- 스키마 없이 사용 가능
- SQL 과 비슷한 방식의 쿼리 사용
- 몽고는 쓰기할때 메모리에 먼저 Write 후에 1분 단위로 Flushing하는 Write back 방식을 사용한기 때문에 write성능이 좋음
- Read시에는 파일의 Index를 메모리에 로딩해 놓고 찾는다(memory mapped file)
- 빠름
- 다양한 기능 제공- JOIN이나 트랜잭션 처리가 불가능
- 디스크에 쓰기가 비동기식으로 이루어진다. 때문에 경우에 따라 데이터가 유실될 가능성도 있다.[ Cassandra & HBase ]
- 카산드라 클러스터 설정 및 구성이 HBase 클러스터 구성보다 훨씬 쉽다.
- 카산드라가 일반적으로 write시 5배 이상의 더 나은 성능, read시 4배 이상의 성능을 보인다.
[ Cassandra & MongoDB ]
- Cassandra 노드가 추가될수록 MonogoDB 보다 훨씬 나은 선형적인 성능 향상을 보인다.
- 다중 Index가 필요한 구조라면 MongoDB를 선택하고, 데이터 항목 변경이 많고 unique access가 많은 경우라면 Cassandra가 적합
- http://db-engines.com/en/system/Cassandra;MongoDB
성능비교