Spark To Cassandra Insert 작업 개편기
<이야기를 시작하기 전에 대량 Insert작업의 문제점>
Datastax에서 제공하는 spark-cassandra-connector_2.11을 사용하여 2억 Row이상이 되는 파일을 읽어 Cassandra에 Insert하는 작업이 있다. 이 작업은 Daily로 진행 된다.
회사 클러스터 자원을 사용했을 때 작업 시간은 대략 30분 정도이다. 하지만 이 작업을 할 때 Cassandra Read 기능은 거의 사용할 수 없을 정도로 불능 상태가 된다.
해당 작업이 수행할 동안 Cassandra의 Read Latency는 다음과 같다. (오전7시30분~ 오전8시까지)
해당 작업이 2억Row가 되는 데이터를 한번에 Insert하는 작업이기 때문에 Spark-Cassandra-connector에서 throughput_mb_per_sec옵션으로 insert throughtput양을 조절해도 워낙 들어가는 양이 많아서 Network I/O 부하가 심해지고 memTable에 작성되는 내용이기 때문에 Memory 사용량 증가와 잦은 compaction으로 C* 전체의 성능이 저하되는 현상이 있다.


즉 C*를 사용하는 Data-API서버의 Response Time을 개선하고 싶은 것이다.
아래는 Data-API서버에 Response Time이 100ms가 넘는 비율을 나타낸 그래프이다.
7시 Bulk Insert작업이 동작하는 시간이다.
일명 불기둥(7시 bulk insert작업동안 C*의 Read성능이 떨어져 API Response Time이 100m가 넘는 것)을 제거하는 것이 이번 프로젝트에 목표다.

기존 방식에서 Read성능이 떨어지는 이유를 write path와 read path보면 알 수 있다.
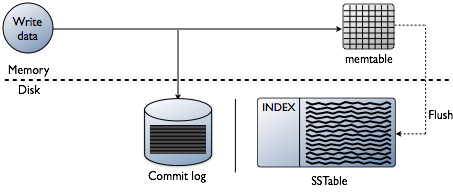
Write path
- client와 node의 process
- client에서 접속한 node가 coordinator의 역할을 하게 된다
- coordinator node는 partitioner를 이용하여 replica node를 찾고 지정된 consistency level을 만족할 만큼의 replica node를 찾지 못하면 바로 에러를 반환한다
- 대상 테이블이 materialized view 테이블의 base 테이블이면 batch log를 생성하고 설정된 consistency level과 관계 없이 내부적으로 replica nodes의 quorum만큼 변경이 반영되게 한다
- coordinator node는 replica node로 write 요청을 보내고, 요청을 받은 node는 write 처리를 수행한다
- cluster가 여러 data center로 구성되어 있으면 다른 data center에 remote coordinator를 선택하여 local coordinator와 같은 처리를 하고, remote replica는 완료 응답을 original coordinator node로 보낸다
- original coordinator node는 timeout까지 replica의 응답을 기다려 client에 응답을 보낸다
- node 안에서 process
- 대상 테이블이 materialized view 테이블이면 partition에 대한 lock을 획득하여 base 테이블의 변경이 다른 write 요청에 의해 변경되지 않고 materialized view 테이블에 반영될 수 있도록 하고 partition을 읽어 materialized view 테이블에 반영할 변화량을 구성한다
- commit log를 쓴다
- 대상 테이블이 materialized view 테이블이면 batch log를 생성하고 materialized view 테이블에 변경을 반영한다
- memtable에 data를 쓴다
- row cache가 있으면 해당 row를 invalidate 처리한다
- commit log나 memtable이 threshold를 넘으면 flush를 schedule에 등록한다
- coordinator가 client로 응답을 보낸다
- schedule에 flush가 등록되어 있으면 memtable을 sstable에 쓰고 commit log를 지우고 compaction이 필요한지 체크 후 필요하면 compaction을 수행한다
Read path
- client와 node의 process
- client에서 접속한 node가 coordinator의 역할을 하게 된다
- coordinator node는 partitioner를 이용하여 replica node를 찾고 지정된 consistency level을 만족할 만큼의 replica node를 찾지 못하면 바로 에러를 반환한다
- coordinator는 dynamic snitch를 이용해 가장 빠른 replica node에 read 요청(full data)를 보내고 다른 replica node에 digest 요청을 보내 read 요청을 보낸 node의 값의 digest와 비교하여 consistency level을 만족하면 client에 응답을 보낸다
- 가장 빠른 replica node에서 받은 값의 digest와 다른 replica node의 digest 값이 다르면 가장 빠른 replica node를 제외한 다른 replica node에 read 요청(full data)를 보내고 결과를 받아 timestamp를 비교하여 각 cell마다 가장 최근값을 client에 응답으로 보내고 값이 맞지 않는 replica node(가장 빠른 replica node 포함)들에 read repair 요청을 보내 최신값으로 동기화한다
- node 안에서 process
-
row cache를 쓰고 있으면 를 확인하여 있으면 응답을 보낸다
row cache
-
row cache에 값이 없으면 를 체크하여 sstable에 값이 있는지 확인한다
bloom filter
-
bloom filter 확인 결과가 true라고 하더라도 는 false positive(실제로는 없는데 있다고 판단) 가능성이 있으므로 를 한 번 더 확인한다
bloom filter
key cache
- key cache에 값이 있으면 그 결과(sstable에서 partition key의 offset)를 이용하여 sstable에서 값을 찾는다
-
key cache에 값이 없으면 에서 partition key에 해당하는 partition index의 offset값을 찾는다(partition key에 딱 맞는 값을 주는 것이 아니라 starting point를 알려줌)
partition summary
- 위에서 찾은 offset 값을 이용하여 sstable에서 요청된 partition key에 맞는 값을 찾는다
- memtable에서 값을 찾고 sstable에서 찾은 값이 있으면 cell별로 최신값으로 merge한다
- row cache를 쓰고 있으면 update한다
- merge된 결과를 client로 반환한다
-
- memtable을 cache처럼 쓰지 않는 이유
- memtable의 값이 항상 최신이라고 볼 수 없다
- 새로운 row가 들어와 memtable에만 값이 있는 경우 bloom filter에서 false가 되어 바로 memtable에서 값을 찾는다
- memtable이 flush가 되어 sstable에 값이 써지면 memtable은 비워지게 된다
- 비워진 memtable에 기존에 들어왔던 row에서 일부 cell들만 update가 된다고 하면 memtable만 보고서 row에 해당하는 모든 cell의 값을 알 수 없다
- memtable은 일반적인 cache라기 보다는 sstable에 값을 쓰기 전에 임시로 값을 저장하고 있는 write-back cache의 일종으로 볼 수 있다
- memtable의 값이 항상 최신이라고 볼 수 없다
spark-cassandra-connector에서 C*에 데이터를 Insert하는 방식은 RDD를 mapPartition 돌면서 Insert문을 만들어 C*에 질의하는 방식이다. 그렇기 때문에 MamTable에서 SSTable로 가는 Flush가 많아지고 SSTable이 많아지면 Compaction수가 많아져 Read작업에 사용될 Memory가 부족해 wirte작업이 끝날때 까지 Read Latency의 값이 매우 크게 나타난다. 또 GC발생횟수가 증가하고, Memory에서 Disk로 Flush가 되기 때문에 System Load도 증가된다.
문제는 실시간으로 C*에서 값을 가져가 사용하는 서비스에 큰 영향을 미친다. spark-cassandra-connector에서 제공하는 방식이 아닌 새로운 방식을 모색하게 되었다. 여러가지 실험을 진행했지만 그 중 SSTableFile을 만들어 직업 C*에 Insert하는 방식을 사용하니 ReadLatency와 C*의 성능 개선을 할 수 있었다.
Cassandra Bulk Insert Lib 구조
라이브러리를 제작할 때 크게 두가지 기능을 구현하면 되었다.
- Make SSTable File
- SSTable File Up Load to Cassandra
이때 Spark를 사용하여, 위 두가지 기능을 분산 처리 하도록 하였다.
작업이 순서는 다음과 같다.
- Read File
- File transform to RDD
- foreachRDD
- Bulk Insert Process
- make SSTable File
- SSTable File Up Load to Cassandra
- Delete SSTable File
작업 시간은 10분정도 이다. (기존 30분에서 20분 가량 줄어 든 시간이다.)
아래 코드는 RDD를 Iterator돌며 SSTableFile제작 → C* upload작업을 나타낸다.
public class SSTableExportProcessor implements Serializable {
public static void process(Iterator<CustomTargetingFitModel> it, SparkCassSSTableLoaderClientStatement clientStatement, int TTL) throws IOException {
String keyspaceName = clientStatement.getKeyspaceName();
String tableName = clientStatement.getTableName();
//ssTable Directory Path에 마지막은 keyspace/tableName으로 해야함.
String tempSSTableDirectoryPath = "/tmp/" + "spark-cass-" + UUID.randomUUID().toString()
+ "/" + keyspaceName + "/" + tableName;
File tempSSTableDirectory = new File(tempSSTableDirectoryPath);
boolean makeDirCheck = tempSSTableDirectory.mkdirs();
if (makeDirCheck) {
//SSTable File 생성작업
CQLSSTableWriter writer =
CQLSSTableWriter.builder()
.inDirectory(tempSSTableDirectory)
.forTable(clientStatement.getTableSchemaStatement())
.using(clientStatement.getInsertStatement(TTL))
.build();
while (it.hasNext()) {
CustomTargetingFitModel row = it.next();
List<Object> rowValues = new ArrayList<>(2);
rowValues.add(row.getUid());
rowValues.add(row.getCode());
writer.addRow(rowValues);
}
writer.close();
//SSTable File cassandar로 load
CqlBulkRecordWriter.ExternalClient externalClient =
new CqlBulkRecordWriter.ExternalClient(clientStatement.getExternalClientConf());
try {
new SSTableLoader(tempSSTableDirectory,
externalClient,
new OutputHandler.LogOutput()).stream().get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
if (tempSSTableDirectory.exists()) {
FileUtils.deleteDirectory(tempSSTableDirectory);
}
}
}
}


매일 오전 7시30분에 Bulk Insert작업이 시작된다. 수정한 코드는 2월 16일에 배포를 했다. SystemLoad와 GC Time이 줄어든 것을 확인할 수 있다. MemTable을 거치지 않으니 당연한 결과이다.

하지만 Read Latency는 크게 변화가 없었다. (혼자 크게 뛰는 장비는 장비 이상으로 추후 제거되었다.)
그래서 원인을 찾아보았다.

위 그래프는 C*를 Datasource로 사용하는 API서버에서 ResponseTime이 100ms가 넘는 비율을 나타낸다.
SSTable File을 이용한 Bulk insert 방식은 7시33분 1분 동안 70%가 넘는 비율이 ResponseTime이 100ms를 넘겼다.
이에 반해 Spark-Cassandra-Connector를 사용한 isnert작업은 10%대를 길게 유지하였다.
Bulk Inert한 테이블의 Compaction Strategy는 LeveledCompactionStrategy이다. 즉 많은 SSTable File이 생성되면 될 수록 Read성능이 떨어진다.(reper. datastax-doc)
기존 작업은 executor하나당 1000개가 넘는 SStable파일이 생성되어 compaction 타임에 C*의 Read성능에 악영향을 미쳤을 것으로 보인다.
그래서 수정된 작업은 다음과 같다.
- Read File
- File transform to RDD
- foreachRDD
- RepartitionByCassandraReplica (option: partitionPerHost = 1)
- Bulk Insert Process
- make SSTable File
- SSTable File Up Load to Cassandra
- Delete SSTable File
즉 1만개가 넘는 SSTableFile 갯수를 Repartitions을 하여 10개로 만들어서 테스트를 하니 API에 100ms넘는 비율이 확연하게 줄어든 것을 알 수 있다.

그리고 7시 불기둥도 사라졌다.

정리
2억 Row이상의 데이터를 C*로 Insert하는 작업을 할때 line-by-line으로 memTable로 insert하는 것 보다 SSTable에 바로 write하는 것이 유리하다.
SSTable에 바로 wirte하는 것이 유리한 점
- System Load 감소
- GC time 감소
- BulkInsert 작업 시간감소로 인해 리소스 제고
- line-by-line insert 작업 보다 나은 Read Latency
새롭게 학습한 내용
C* doc에서 권장하는 Heap Size는 8GB였다. 그래서 장비의 memory에 큰 관심이 없었다. 하지만 compaction, read할때 장비의 memory가 크면 클 수록 유리하다는 것을 doc(datastax-doc)을 읽으면서 알 수 있었다.
특히 compaction이 발생할때…
그리고 SSTable File용량보다는 File갯수가 성능에 더 큰 영향을 준다. 즉 SSTableFile갯수가 적을 수록 성능에 더 유리하다.
아래는 C*에서 사용하는 Memory구조이다.
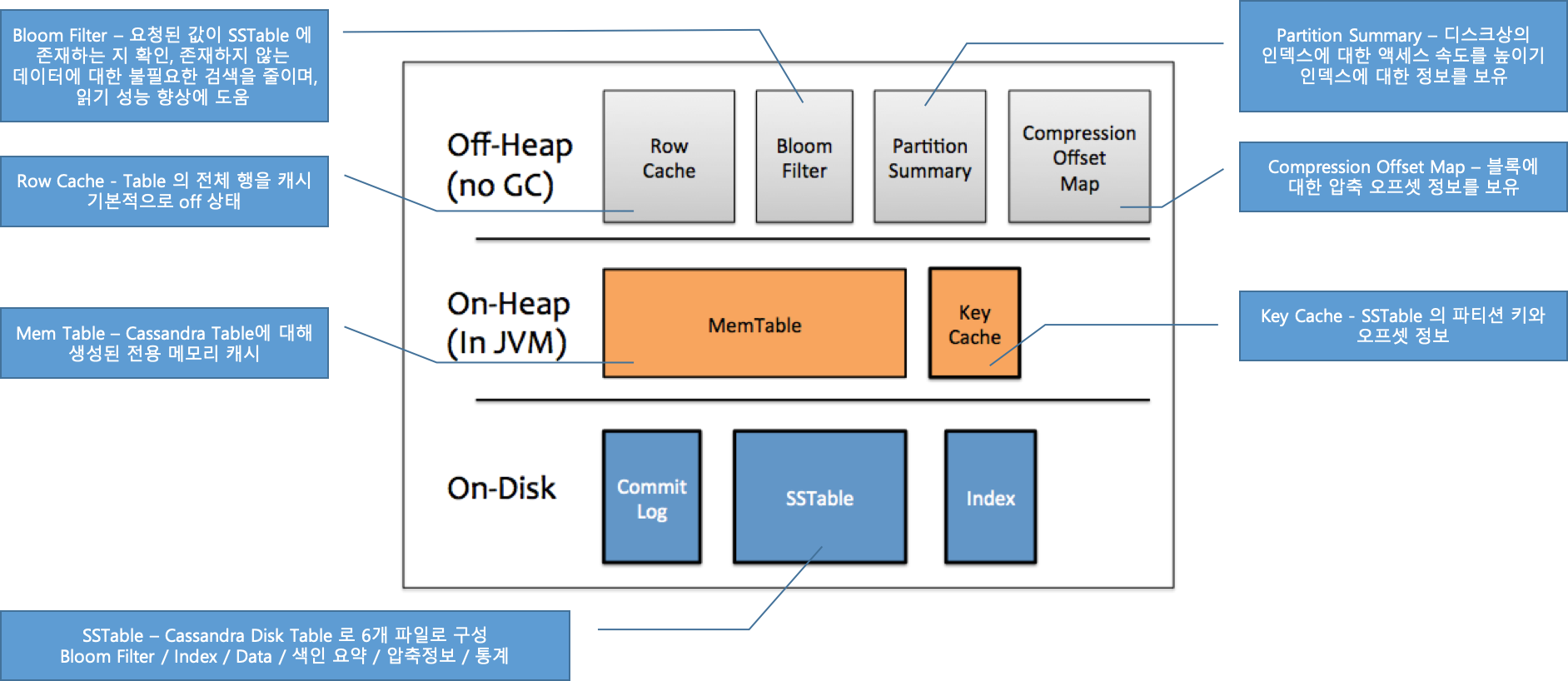
<추가> Spark Lib제작 (2019.08.26)
위 내용을 Spark Lib으로 제작하여 배포하였다.
- Spark2CassandraBulkLoad (해당 레포에 많은 관심과 기여 부탁드립니다.)
- spark-packages에도 upload하였습니다. 많은 관심 부탁드립니다.
SBT
libraryDependencies += "com.joswlv.spark.cassandra.bulk" %% "Spark2CassandraBulkLoad" % "1.0.1"
Maven
<dependency>
<groupId>com.joswlv.spark.cassandra.bulk</groupId>
<artifactId>Spark2CassandraBulkLoad</artifactId>
<version>1.0.1</version>
</dependency>
gradle
compile 'com.joswlv.spark.cassandra.bulk:Spark2CassandraBulkLoad:1.0.1'
Usage
Bulk Loading into Cassandra
// Import the following to have access to the `bulkLoadToCass()` function for RDDs or DataFrames.
import com.joswlv.spark.cassandra.bulk.rdd._
import com.joswlv.spark.cassandra.bulk.sql._
// Specify the `keyspaceName` and the `tableName` to write.
rdd.bulkLoadToCass(
keyspaceName = "keyspaceName",
tableName = "tableName"
)
// Specify the `keyspaceName` and the `tableName` to write.
df.bulkLoadToCass(
keyspaceName = "keyspaceName",
tableName = "tableName"
)